John Snow Labs developed LangTest to address biases in language models. The library provides comprehensive tests to detect biases in language models. We introduce an end-to-end NLP pipeline, which involves training, evaluating, testing for biases, augmenting the dataset, retraining, and comparing models. This pipeline offers three advantages: comprehensive bias detection, data-driven bias mitigation, and iterative improvement. The blog provides an example of how to use the pipeline with a single command line.

Introduction
As the field of Natural Language Processing (NLP) progresses, the deployment of Language Models (LMs) has become increasingly widespread. However, there is growing concern about biases present in these models, which can have profound societal implications. To address this issue, at John Snow Labs we are developing the LangTest library. In this article we present a significant leap forward by introducing end-to-end pipelines. Throughout the blog we will explore the underlying concepts and understand how the users can benefit from it.
Detecting Biases in Language Models
Detecting biases in language models is critical for ensuring fairness and promoting ethical practices in AI. Language models, such as ChatGPT, can inadvertently perpetuate stereotypes and exhibit biased behaviour due to the data they were trained on. LangTest has been developed to tackle this challenge head-on by providing a set of comprehensive tests to uncover potential biases in LMs.
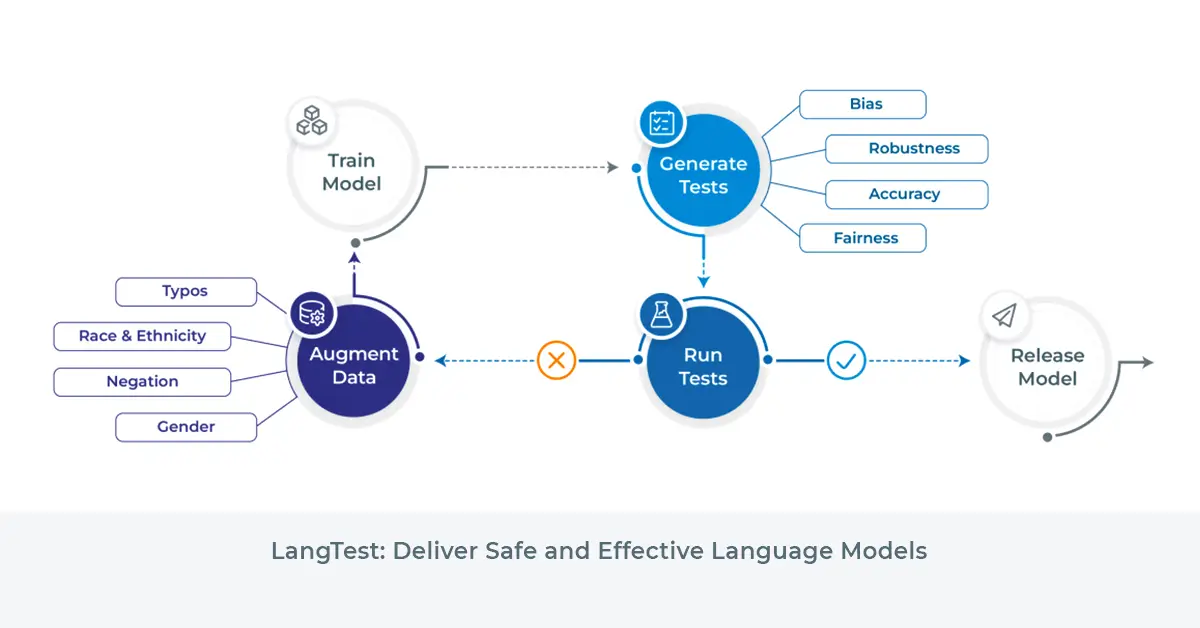
The End-to-End Pipeline
The recently added end-to-end language pipeline in LangTest streamlines the bias, fairness or robustness detection process, making it more efficient, reliable, and accessible to developers and researchers alike. The pipeline workflow consists of the following key steps:
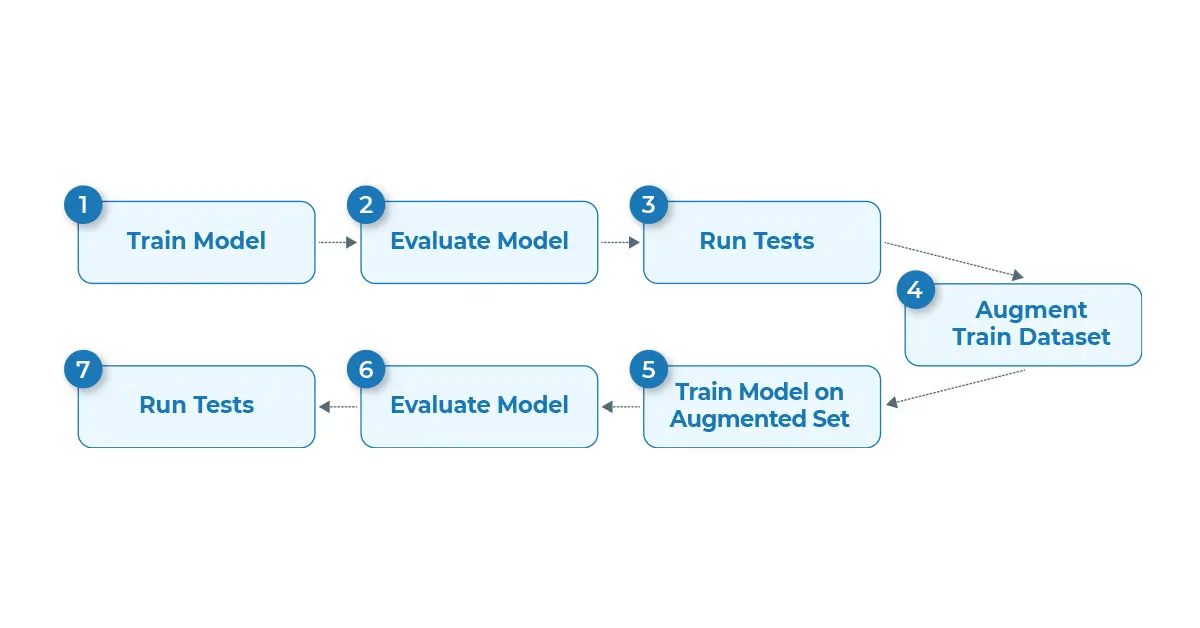
- Train a Language Model on your dataset: To begin, the user provides a dataset to train an initial language model. This dataset should be diverse and representative of the real-world scenarios where the model will be deployed.
- Evaluate the model on the test set: Once your model is trained, it is evaluated on the provided test dataset to assess its performance on unseen data.
- Test the model on a set of tests: The pipeline then leverages the comprehensive set of bias tests provided by LangTest to evaluate the model’s behaviour for potential biases. These tests are carefully designed to capture various forms of bias, including gender, race, and cultural biases.
- Augment the training set based on the tests outcomes: The pipeline uses the results from the bias tests to identify and augment the training dataset with specific counterexamples. These counterexamples are carefully crafted to reduce biases and encourage the model to make more equitable predictions.
- Retrain your model on the augmented training data: With the augmented training dataset, the model is retrained to incorporate the new information and further reduce biases in its output.
- Evaluate the freshly trained model: The retrained model is evaluated on the same test dataset to measure its improved performance compared to the initial model.
- Run tests and compare the two models performance: Finally, the pipeline will test the newly trained model and provides a detailed performance comparison between the initial and retrained models, highlighting the effectiveness of the bias mitigation process.
In a nutshell the newly added pipelines offer the three advantages:
- Comprehensive Bias Detection: The pipeline’s integration of LangTest bias tests ensures that a wide range of biases is identified, allowing developers to gain a holistic understanding of their model’s behaviour.
- Data-Driven Bias Mitigation: By augmenting the training dataset based on the test outcomes, the pipeline offers a data-driven approach to bias mitigation. This leads to more accurate and targeted improvements in the model’s performance.
- Iterative Improvement: The pipeline enables an iterative process of training, evaluation, and augmentation, making it easier for developers to refine their models over time and achieve higher levels of fairness.
Let’s get started!
Now that we understand the power of those pipelines let us understand how we can use them on a real life example and with a single line of code! We will show here how to train and fix a named-entity recognition model.
First of all we need to install the package:
pip install langtest
Now that the package is installed choose your favourite model and dataset! For the sake of this example we chose to use bert-base-cased and train it on the ConLL dataset. All you need to do is to run the following command line:
python3 langtest/pipelines/transformers/ner_pipeline.py run \
--model-name="bert-base-cased" \
--train-data=train.conll \
--eval-data=test.conll \
--training-args='{"per_device_train_batch_size": 8}'
And that’s it, you have successfully trained a BERT model on your dataset, identify its weaknesses and fixed them!
Here is a quick look at the output of the pipeline:
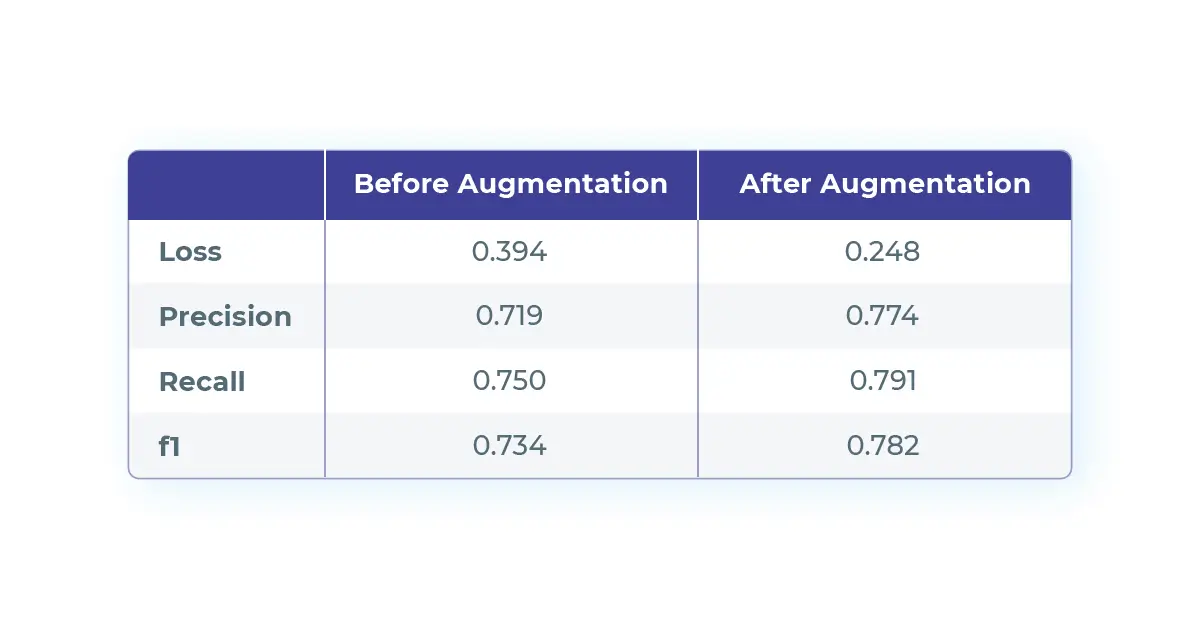
We can clearly observe that the model’s performance on the provided test set significantly increased thanks to the dataset augmentation. In fact, under the hood langtest has ran several tests to identify weaknesses. Once those flaws were identified langtest generated new samples to train the model on those shortcomings. Note that the evaluation dataset is kept unchanged.
You can now load and use the model trained on the augmented train dataset using the transformers library:
from transformers import AutoTokenizer, AutoModel
model = AutoModel.from_pretrained("augmented_checkpoints/")
tokenizer = AutoTokenizer.from_pretrained("augmented_checkpoints/")
What Happens Under the Hood
To achieve such a level of simplicity we use a combination of tools:
- Langtest: to perform the weaknesses detection and dataset augmentation
- Metaflow: to orchestrate the different steps of the pipeline
- Transformers: to define the model and perform the actual training
Note that we plan on supporting other third party libraries than transformers to train and define language models. In order to customise training one can pass training arguments through the --training-args flag, these parameters will directly be passed to the transformers.Trainer . Also, in the above example we use the default langtest tests configuration. One can specify its own tests and values through the --config flag (see here for me information).
Conclusion
The end-to-end language pipeline in LangTest empowers NLP practitioners to tackle biases in language models with a comprehensive, data-driven, and iterative approach. As we strive for responsible AI development, this new feature in LangTest is a step forward in promoting easy to use ethical AI practices and ensuring the responsible deployment of language models in real-world scenarios.
FAQ
What are the main stages of LangTest’s end-to-end pipeline?
The NER pipeline includes model training, evaluation, bias testing, data augmentation, retraining, and model comparison, creating a fully iterative loop for continuous fairness improvement.
How does LangTest detect bias in language models?
It runs a suite of comprehensive bias tests—like demographic name and pronoun swaps—on models to reveal differences in performance across sensitive groups.
How does data augmentation reduce model bias?
When tests surface weaknesses, LangTest augments the dataset with targeted examples (e.g., underrepresented names), then retrains and reevaluates the model to improve fairness.
Can LangTest compare multiple models automatically?
Yes—the pipeline supports model comparison, generating reports that highlight performance and fairness differences between model versions.
How do developers run the full pipeline in a single step?
LangTest provides a command-line interface where a single command trains, biases, augments, retrains, and outputs a final evaluation—simplifying the bias mitigation workflow.
