










The field of Natural Language Processing (NLP) has been greatly impacted by the advancements in machine learning, leading to a significant improvement in linguistic understanding and generation. However, new challenges have emerged with the development of these powerful NLP models. One of the major concerns in the field is the issue of robustness, which refers to a model’s ability to consistently and accurately perform on a wide range of linguistic inputs, including those that are not typical.
Is Your NLP Model Truly Robust? ?
It is important to identify problems with NLP models in order to ensure that they perform well across a variety of real-world situations. There are several ways to do this.
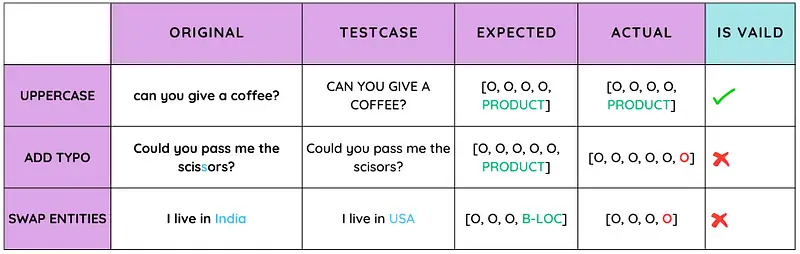
- Researchers can test the model’s adaptability and resistance to changes in sentence structure, punctuation, and word order by altering the input.
- Introducing spelling mistakes, typos, and phonetic variations can help determine the model’s ability to handle noisy data.
- Evaluating the model’s response to different levels of politeness, formality, or tone can reveal its sensitivity to context.
Additionally, testing the model’s understanding of ambiguous or figurative language can reveal its limitations. Swapping key information or entities within a prompt can expose whether the model maintains accurate responses. Finally, testing the model’s performance on out-of-domain or niche-specific input can reveal its generalization abilities. Regular testing using these methodologies can identify and address problems, helping NLP models to become more effective and reliable tools for various applications.
In this blog post, we will be testing the robustness of the NERPipeline model, which is good in the f1 score, and evaluating its performance.
“With a high-quality dataset, you can build a great model. And with a great model, you can achieve great things.”
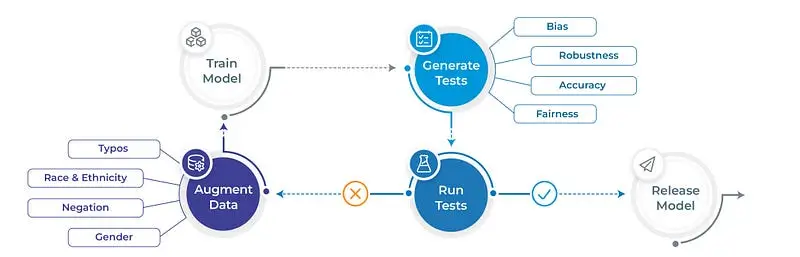
Improve robustness automatically with data augmentation
Data augmentation is a widely used technique in the field of Natural Language Processing (NLP) that is aimed at increasing the size and diversity of the training data for language models and other NLP tasks. This technique can involve creating new training examples from existing data or generating entirely new data.
The benefits of data augmentation are manifold. Firstly, it can help to reduce overfitting by increasing the size and diversity of the training data. Overfitting occurs when a model learns the training data too well, and as a result, performs poorly on new data. By using data augmentation, the model is exposed to a larger and more diverse set of data, which helps it to better generalize to new data. Secondly, data augmentation can improve the robustness of the model by exposing it to a broader range of linguistic variations and patterns. This helps to make the model more resistant to errors in the input data.
In the realm of NLP, the Langtest library offers two types of augmentations: Proportional Augmentation and Templatic Augmentation. Proportional Augmentation is based on robustness and bias tests, while Templatic Augmentation is based on templates provided by user input data. The library is also continually developing new augmentation techniques to enhance the performance of NLP models.
Proportional Augmentation can be used to improve data quality by employing various testing methods that modify or generate new data based on a set of training data. This technique helps to produce high-quality and accurate results for machine learning, predictive modeling, and decision-making. It is particularly useful for addressing specific weaknesses in a model, such as recognizing lowercase text.
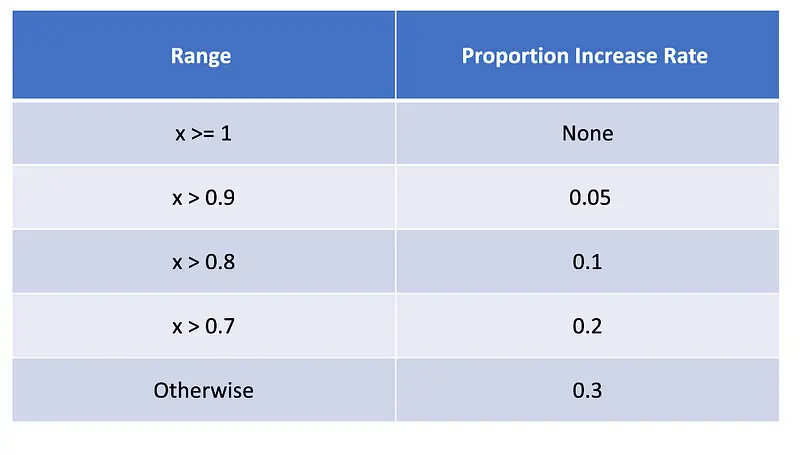
We use the minimum pass rate and pass rate figures from the Harness testing report for the provided model to calculate a proportion by default. Let’s call the result of comparing the minimum pass rate with the pass rate “x.” If x is equal to or greater than 1, the situation is undefined or not applicable. If x falls between 0.9 and 1, the assigned value is 0.05, indicating a moderate increase. For x between 0.8 and 0.9, the corresponding value becomes 0.1, indicating a relatively higher increase. Similarly, when x is between 0.7 and 0.8, the value becomes 0.2, reflecting a notable increase. If x is less than or equal to 0.7, the value is 0.3, representing a default increase rate for smaller proportions. This systematic approach classifies varying proportion increase rates based on the x value, resulting in a structured output that adapts to different input scenarios.
The Langtest library provides a range of techniques for generating datasets by using proportional augmentation. This can be accomplished by specifying the export_mode parameter, which offers various values such as add, inplace, and transformed. In order to gain a better understanding of the export_mode parameter and its different values, you can refer to the accompanying images.
Add mode: It is important to note that any new sentences that are generated will be added to the existing file.
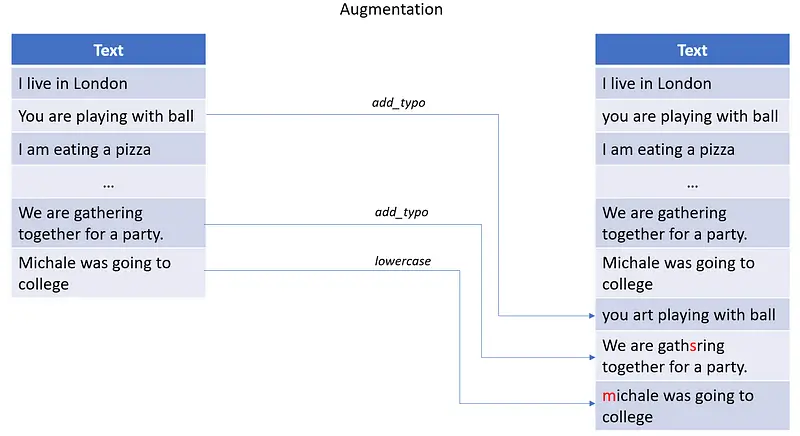
Inplace mode: It is important to note that edit sentences with respect to test types from the harness by picking randomly them from the given dataset.

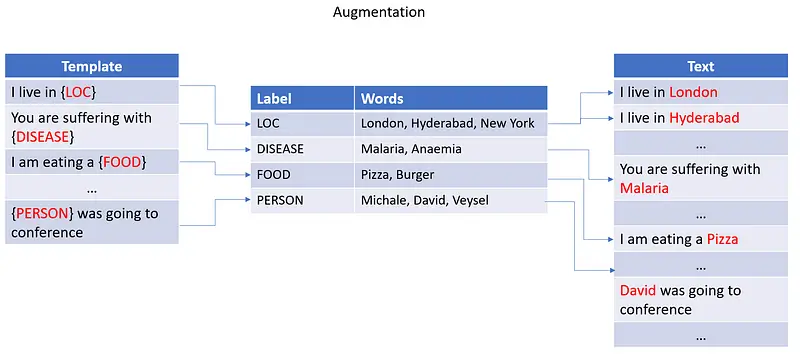
Templatic Augmentation, on the other hand, involves taking pre-existing templates or patterns and generating new data that is structurally and contextually similar to the original input. This method relies heavily on the templates provided by the user. By using this technique, NLP models can be further refined and trained to better understand the nuances of language.
The Langtest library offers a feature called “templatic augmentation” that can generate a fresh dataset by utilizing provided templates. The process involves extracting labels and corresponding values from an existing dataset and then replacing those values with the provided templates using the labels from the dataset. To visualize this process, please refer to the figure below.
In summary, data augmentation is a critical aspect of data management in NLP. By increasing the size and diversity of the training data, models can be better trained to handle a wide range of linguistic variations and patterns. However, it is important to note that augmentation is not a panacea that can fix fundamentally flawed models. While data augmentation can certainly help to improve the performance and robustness of NLP models, it is just one aspect of a broader set of techniques and tools that are required to develop high-quality and effective language models.
Let me introduce you to the Langtest.
Langtest is an open-source Python library that provides a suite of tests to evaluate the robustness, bias, toxicity, representation, and accuracy of natural language processing (NLP) and large language models (LLMs). The library includes a variety of tests, each of which can be used to assess a model’s performance on a specific dimension. For example, the robustness tests evaluate a model’s ability to withstand adversarial attacks, the bias tests evaluate a model’s susceptibility to demographic and other forms of bias, and the toxicity tests evaluate a model’s ability to identify and avoid toxic language.
Langtest is designed to be easy to use, with a one-liner code that makes it easy to run tests and evaluate a model’s performance. The library also includes several helpful features, such as a built-in dataset of test cases and save or load functionality, that can be used to track a model’s performance over time.
Langtest is a valuable tool for data scientists, researchers, and developers working on NLP and LLMs. The library can help to identify potential problems with a model’s performance, and it can also be used to track a model’s performance over time as it is trained and fine-tuned.
Here are some of the benefits of using Langtest:
Easy to use: Langtest has a one-liner code that makes it easy to run tests and evaluate a model’s performance.
Versatile: Langtest includes a variety of tests that can be used to evaluate a model’s performance on a variety of dimensions.
Accurate: Langtest uses a variety of techniques to ensure that the results of its tests are accurate.
Open source: Langtest is open source, which means that anyone can use it for free.
from langtest import Harness
harness = Harness(task="ner",
model="en_core_web_sm",
data="path/to/sample.conll",
hub="spacy")
# generate and evaluate the model
harness.generate().run()report()
Let’s enhance the Model Performance
To improve the performance of a model, it is important to test it thoroughly. One way to achieve this is by augmenting the training data. This involves adding more data to the existing training set in order to provide the model with a wider range of examples to learn from. By doing so, the model can improve its accuracy and ability to generalize to new data. However, it is important to ensure that the additional data is relevant, and representative of the problem being solved.
The following are steps to augmentation over train data with the specified model.
- Initialize the model from johnsnowlabs.
from johnsnowlabs import nlp
from langtest import Harness
documentAssembler = nlp.DocumentAssembler()\
.setInputCol("text")\
.setOutputCol("document")
tokenizer = nlp.Tokenizer()\
.setInputCols(["document"])\
.setOutputCol("token")
embeddings = nlp.WordEmbeddingsModel.pretrained('glove_100d') \
.setInputCols(["document", 'token']) \
.setOutputCol("embeddings")
ner = nlp.NerDLModel.load("models/trained_ner_model") \
.setInputCols(["document", "token", "embeddings"]) \
.setOutputCol("ner")
ner_pipeline = nlp.Pipeline().setStages([
documentAssembler,
tokenizer,
embeddings,
ner
])
ner_model = ner_pipeline.fit(spark.createDataFrame([[""]]).toDF("text"))
- Initialize the
Harnessfrom thelangtestlibrary in Python with an initialized model from johnsnowlabs.
harness = Harness(
task="ner",
model=ner_model,
data="sample.conll",
hub="johnsnowlabs")
- Configuring the tests by using the
configure()function from the harness class, as seen below. After performinggenerate()andsave()for saving produced test cases, executerun()and generate a report by callingreport().
harness.configure({
'tests': {
'defaults': {'min_pass_rate': 0.65},
'robustness': {
'uppercase': {'min_pass_rate': 0.80},
'lowercase': {'min_pass_rate': 0.80},
'titlecase': {'min_pass_rate': 0.80},
'strip_punctuation': {'min_pass_rate': 0.80},
'add_contraction': {'min_pass_rate': 0.80},
'american_to_british': {'min_pass_rate': 0.80},
'british_to_american': {'min_pass_rate': 0.80},
'add_context': {
'min_pass_rate': 0.80,
'parameters': {
'ending_context': [
'Bye',
'Reported'
],
'starting_context': [
'Hi',
'Good morning',
'Hello']
}
}
}
}
})
# testing of model harness.generate().run().report()
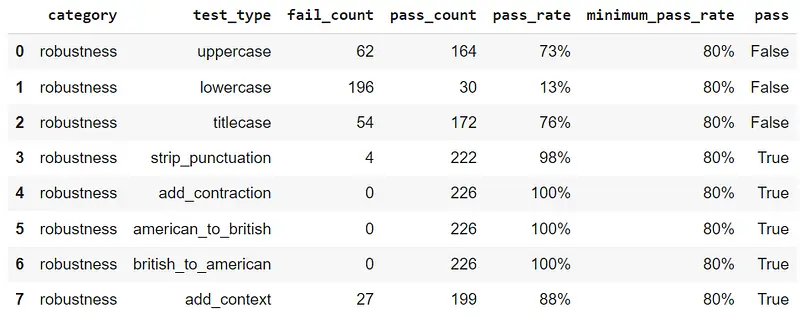
Augment CoNLL Training Set Based on Test Results
The proportion values are automatically calculated, but if you wish to make adjustments, you can modify values by calling the augment method in the Harness class within the Langtest library. You can use the Dict or List format to customize the proportions.
In the Dict format, the key represents the test type and the value represents the proportion of test instances that will be augmented with the specified type. For example, ‘add_typo’ and ‘lowercase’ have proportions of 0.3 each.
custom_proportions = {
'uppercase':0.3,
'lowercase':0.3
}
In the List format, you simply provide a list of test types to select from the report for augmentation, and the proportion values of each test type are calculated automatically. An example of augmentation with custom proportions can be seen in the following code block.
custom_proportions = [
'uppercase',
'lowercase',
]
Let’s augment the train data by utilizing the harness testing report from the provided model.
# training data
data_kwargs = {
"data_source" : "path/to/conll03.conll",
}
# augment on training data
harness.augment(
training_data = data_kwargs,
save_data_path ="augmented_conll03.conll",
export_mode="transformed")
Train New NERPipeline Model on Augmented CoNLL
In order to continue, you must first load the NERPipeline model and begin training with the augmented data. The augmented data is created from the training data by randomly selecting certain portions and modifying or adding to them according to the test_type. For instance, if a dataset contains 100 sentences and the model does not pass the lowercase test out of given tests, the data proportion can be determined by dividing the minimum pass rate by the pass rate.
This will ensure that the training process is consistent and effective.
# load and train the model
embeddings = nlp.WordEmbeddingsModel.pretrained('glove_100d') \
.setInputCols(["document", 'token']) \
.setOutputCol("embeddings")
nerTagger = nlp.NerDLApproach()\
.setInputCols(["document", "token", "embeddings"])\
.setLabelColumn("label")\
.setOutputCol("ner")\
.setMaxEpochs(20)\
.setBatchSize(64)\
.setRandomSeed(0)\
.setVerbose(1)\
.setValidationSplit(0)\
.setEvaluationLogExtended(True) \
.setEnableOutputLogs(True)\
.setIncludeConfidence(True)\
.setOutputLogsPath('ner_logs')
training_pipeline = nlp.Pipeline(stages=[
embeddings,
nerTagger
])
conll_data = nlp.CoNLL().readDataset(spark, 'augmented_train.conll')
ner_model = training_pipeline.fit(conll_data)
ner_model.stages[-1].write().overwrite().save('models/augmented_ner_model')
harness = Harness.load(
save_dir="saved_test_configurations",
model=augmented_ner_model,
task="ner")
# evaluating the model after augmentation
harness.run().report()
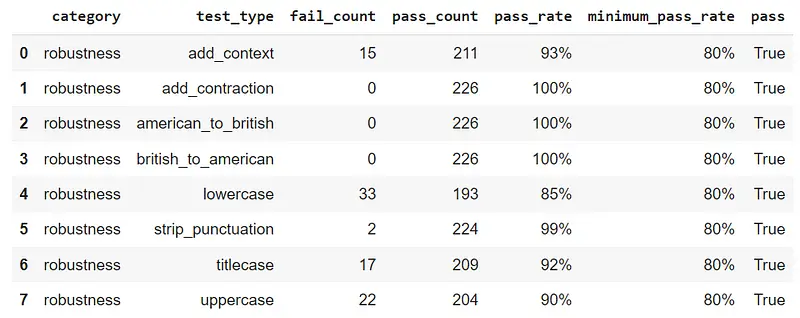
Conclusion
To summarize our findings, it has been noted that the NERPipeline model exhibits subpar performance in the lowercase test. However, after applying augmentation in the form of lowercase, there has been a lot of improvement in its performance. It is important to consider these observations when evaluating the effectiveness of the NERPipeline model in various applications.

Based on the chart provided, it is evident that the lowercase test has improved 8 times before augmentation results. Similarly, we can also see improvements in the remaining tests. If you’re looking to improve your natural language processing models, then it might be worthwhile to consider utilizing Langtest(pip install langtest). Don’t hesitate any longer, take action and start enhancing your NLP models today.
Have you tried using the Proportional Augmentation Notebook? click here
FAQ
What is automated data augmentation in the context of LangTest?
It’s the process where LangTest uses test results (e.g., failing lowercase robustness) to automatically generate new training examples that address identified weaknesses, improving model diversity and resilience.
What types of augmentation does LangTest support?
LangTest provides two methods: Proportional Augmentation, which adjusts based on test pass rates, and Templatic Augmentation, which uses user-defined templates to create structurally varied input data.
How does proportional augmentation determine how much to add?
It calculates the ratio between actual and minimum pass rates, mapping it to preset increment values (e.g., 0.3 for <70% pass), then applies that rate to generate new examples proportionally.
Can LangTest use the augmented data to retrain models?
Yes—after augmentation, the enhanced dataset can be used to fine‑tune or retrain the model (like an NER pipeline), resulting in improved performance on previously weak test categories.
Why is automated augmentation critical for model robustness?
It removes manual guesswork, directly targets identified weaknesses, and systematically increases training diversity—leading to models that generalize better to real-world noisy inputs like typos, odd formatting, or domain shifts.
