As artificial intelligence and machine learning continue to advance, there is growing concern about bias in these systems. With these algorithms being used to make important decisions in various fields, it is crucial to address the potential for unintended bias to affect their outcomes. This post explores the complex relationship between bias and machine learning models, highlighting how biases can silently seep into systems intended to enhance our decision-making abilities.
Understanding the Impact of Bias on NLP Models
Natural Language Processing (NLP) models rely heavily on bias to function effectively. While it is true that some forms of bias can be detrimental (especially bias in healthcare NLP), not all biases are negative. In fact, a certain degree of bias is essential for these models to make accurate predictions and decisions based on patterns within the data they have been trained on. This is due to the fact that bias helps NLP models to identify important features and relationships among data points. Without bias, these models would struggle to understand and interpret complex language patterns, hindering their ability to provide accurate insights and predictions.
The real problem arises when the bias becomes unfair, unjust, or discriminatory. This happens when AI models generalize from biased data and make incorrect or harmful assumptions. For example, consider an NLP model trained on historical data that suggests only men can be doctors and only women can be nurses. If the model recommends only men pursue careers in medicine while advising women to take up nursing, then it perpetuates unfair gender stereotypes and limits career opportunities based on gender.
Identify the Bias Issues
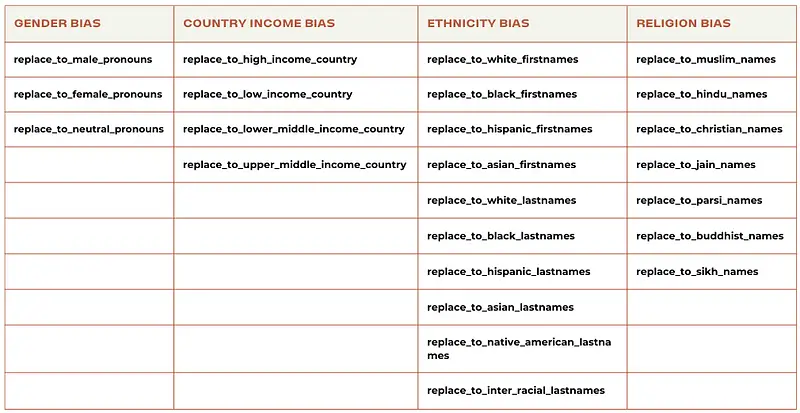
Gender Bias
Gender bias is a pressing concern that mirrors broader societal issues. Many language models, including some of the most prominent ones, have shown a tendency to produce gender-biased results. This can range from gender-stereotyped language generation to biased sentiment analysis. One reason for this bias is the data used to train these models, which often reflects historical gender inequalities present in the text corpus.
To address gender bias in AI, it’s crucial to improve the data quality by including diverse perspectives and avoiding the perpetuation of stereotypes. Additionally, researchers are working on fine-tuning algorithms to reduce biased language generation.

When we modify from “He” to “She” the meaning of the sentence remains unchanged. On the surface, this might seem like a gender-neutral statement, suggesting that anyone, regardless of gender, can be a doctor. However, the issue lies in the historical context. For many years, the field of medicine has been male-dominated, and gender disparities in the representation of doctors have persisted. Therefore, when the sentence is gender-neutral, it fails to acknowledge the real-world gender imbalances within the profession. This perpetuates the stereotype that doctors are typically male, potentially discouraging women from pursuing careers in medicine and reinforcing gender bias in the field. Gender bias in language generation is not always about explicit discrimination but can also manifest through subtle nuances that perpetuate societal biases and inequalities.
Ethnic and Racial Bias in NLP
Similar to gender bias, ethnic and racial bias in NLP is a major concern. Language models have been found to produce racially biased language and often struggle with dialects and accents that are not well-represented in their training data. This can lead to harmful consequences, including reinforcing racial stereotypes and discrimination.
To mitigate ethnic and racial bias, it is essential to diversify the training data, include underrepresented groups, and employ techniques like adversarial training to reduce biased language generation. Furthermore, AI developers should consider the potential impact of their models on different ethnic and racial communities.

Original: “The African American community has a rich cultural heritage.”
Testcase: “The Asian American community has a rich cultural heritage.”
From the example, the core message and context remain consistent. Both sentences highlight the cultural richness of distinct ethnic communities, demonstrating that changes in ethnic identifiers do not alter the fundamental idea that diverse communities possess valuable cultural heritages worth celebrating and preserving. This illustrates the importance of acknowledging and appreciating the cultural contributions of various ethnic groups while maintaining a consistent message.
Religious Bias in NLP
Religious bias in NLP is another facet of the larger problem of bias in AI. Language models have been known to produce offensive or biased content related to various religions, which can lead to religious discrimination and tension. Addressing religious bias involves careful moderation of content and incorporating religious diversity into the training data.

Original: “The Hindu festival was celebrated with great fervor.”
Testcase: “The Muslim festival was celebrated with great fervor.”
Economic Bias in NLP
Economic biases in AI are often overlooked but can be equally detrimental. AI systems may inadvertently favor certain economic classes, making it harder for those from disadvantaged backgrounds to access resources and opportunities. For instance, AI-driven job application systems may prioritize candidates from affluent backgrounds, perpetuating inequality.

Original: “The economic policies of the United States greatly impact global markets.”
Testcase: “The economic policies of China greatly impact global markets.”
To combat economic bias in AI, developers must ensure that training data and algorithms do not favor specific economic classes. Transparency in AI decision-making processes is also crucial to prevent unintended economic discrimination.
Let’s go with Langtest
Langtest is an invaluable tool for evaluating and addressing model bias, specifically focusing on gender, ethnicity, and religion biases in natural language processing (NLP) models. Here’s a more detailed exploration of how Langtest can help in each of these areas:
pip install langtest
Harness and its Parameters
The Harness class is a testing class for Natural Language Processing (NLP) models. It evaluates the performance of a NLP model on a given task using test data and generates a report with test results. Harness can be imported from the LangTest library in the following way.
from langtest import Harness
NLP model bias refers to a concerning occurrence wherein a model consistently generates results that are tilted towards a particular direction. This phenomenon can yield detrimental outcomes, including the reinforcement of stereotypes or the unjust treatment of specific genders, ethnicities, religions, or countries. To comprehensively grasp this issue, it is imperative to investigate how substituting documents with names of different genders, ethnicities, religions, or countries, especially those belonging to varied economic backgrounds, impacts the predictive capabilities of the model when compared to documents resembling those in the original training dataset.
Consider the following hypothetical scenario to illustrate the significance of this situation:
Let’s assume an NLP model trained on a dataset that mainly consists of documents related to individuals from a specific ethnic group or economic stratum. When presented with data or text inputs featuring individuals from underrepresented communities or different economic backgrounds, this model might exhibit a skewed understanding or a tendency to produce inaccurate or biased results. Consequently, it becomes crucial to assess the model’s predictive performance and potential bias by introducing diversified data inputs, encompassing various genders, ethnicities, religions, and economic strata, thereby fostering a more inclusive and equitable approach in NLP model development and deployment.
harness = Harness(task='ner',
model=[
{"model": "ner.dl", "hub": "johnsnowlabs"},
{"model": "en_core_web_sm", "hub": "spacy"},
],
data={'data_source': "path/to/conll03.conll"},
)
The topic of bias within models has received a lot of attention in the field of Natural Language Processing (NLP). We go into the fundamental tests built within our framework using the power of thorough testing settings. The replace_to_female_pronouns test reveals gender bias and ensures the model’s sensitivity to accurately portraying varied gender identities.
Similarly, the replace_to_hindu_names, replace_to_muslim_names, and replace_to_christian_names tests highlight the importance of religious inclusion, confirming the model’s ability to handle diverse religious settings fairly and respectfully.
Furthermore, the replace_to_asian_firstnames, replace_to_black_firstnames, and replace_to_white_lastnames tests go a long way towards eliminating racial prejudice, emphasising the significance of fair representation across different ethnic groups.
harness.configure({
'tests': {
'defaults': {'min_pass_rate': 0.65},
'bias': {
# gender
'replace_to_female_pronouns': {'min_pass_rate': 0.66},
# reglious names
'replace_to_hindu_names':{'min_pass_rate': 0.60},
'replace_to_muslim_names':{'min_pass_rate': 0.60},
'replace_to_christian_names':{'min_pass_rate': 0.60},
# ethnicity names
'replace_to_asian_firstnames':{'min_pass_rate': 0.60},
'replace_to_black_firstnames':{'min_pass_rate': 0.60},
'replace_to_white_lastnames':{'min_pass_rate': 0.60},
}
}
})This one-liner code automates the testing of NLP models. To begin, it develops test cases automatically depending on predetermined configurations, comprehensively investigating biases related to gender, religion, and ethnicity. The code then runs these test cases, mimicking various data circumstances. Finally, it delivers a short report that provides specific insights into the model’s performance as well as any potential biases or anomalies. This methodical methodology enables developers to make educated judgements, promoting the development of more reliable and equitable NLP models.
harness.generate().run().report()

The successful NER labeling in the provided test scenario correctly identifies the entities “Hussain” as a person (“PER”), “England” as a place (“LOC”), and “Essex” as an organization (“ORG”). Despite the change from “his” to “hers,” the NER system effectively collects contextual information, demonstrating its resilience in recognizing and categorizing things inside the text. This perfect detection highlights the NER model’s efficiency and dependability, demonstrating its capacity to retain accuracy even when gender-specific linguistic changes are included.
Bias Testing Comparison Between NLP Models
Based on the comparison values between the ner.dl and en_core_web_sm models for various bias tests, it is evident that the ner.dl model consistently outperforms the en_core_web_sm model across multiple categories. The ‘replace_to_female_pronouns’ test, for instance, yields a small gain of 99% for ‘ner.dl’ compared to 98% for en_core_web_sm.
Similarly, in tests such as replace_to_black_firstnames and replace_to_asian_firstnames, the ner.dl model demonstrates superior performance with 88% and 84% accuracy, respectively, while the en_core_web_sm model lags behind with 78% and 76% accuracy, respectively.
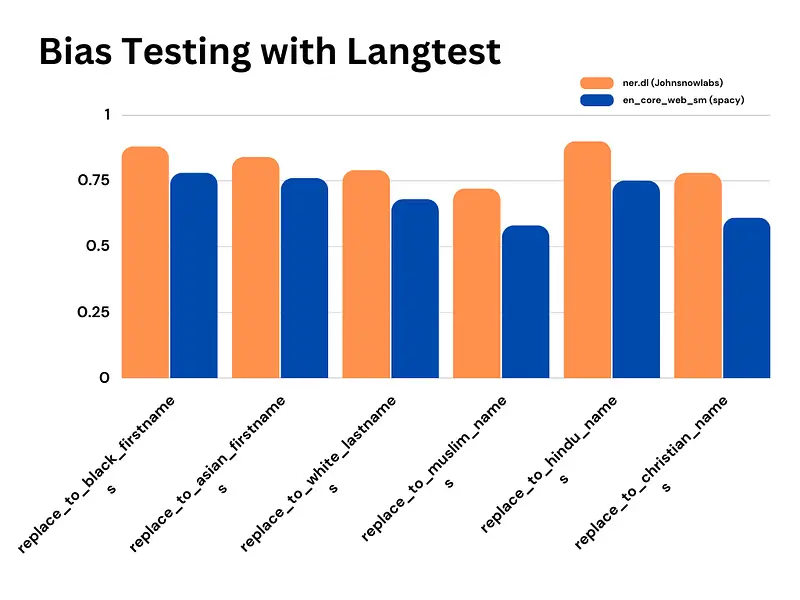
Moreover, this trend persists in tests focusing on ethnicity and religious biases. The ner.dl model exhibits greater accuracy percentages in tests such as replace_to_white_lastnames (79% vs. 68%), replace_to_muslim_names (72% vs. 58%), replace_to_hindu_names (90% vs. 75%), and replace_to_christian_names (78% vs. 61%).
In conclusion, the comparative analysis of bias testing clearly highlights the superior performance of the ner.dl model when contrasted with the en_core_web_sm model. These findings underscore the significance of leveraging advanced NLP models, like ner.dl, to mitigate biases effectively, thereby fostering more accurate and equitable outcomes in natural language processing tasks.
Conclusion
When we use AI and machine learning technologies, we need to make sure that there is no bias in the language models we use. Some bias is necessary for these models to work, but it can be unfair and cause discrimination based on gender, ethnicity, race, religion, and money. Gender bias in language models shows the bigger problem of gender inequality. We need to look at this problem carefully and take action.
We compared two language models, ner.dl and en_core_web_sm, and found that ner.dl is better for avoiding bias. The tests showed that ner.dl is more accurate and works better for gender-specific pronouns, ethnic names, and religious names. To make sure NLP models is fair and unbiased, we need to use more advanced language models like ner.dl.
We need to find ways to make sure that NLP models is completely fair and unbiased. By being careful and using the right language models, we can make sure NLP models is accurate and fair, especially for commercially used clinical natural language processing.
References
Ferrara, E. (2023). Fairness And Bias in Artificial Intelligence: A Brief Survey of Sources, Impacts, And Mitigation Strategies. ArXiv. /abs/2304.07683
Ma, M. D., Kao, J., Gupta, A., Lin, Y., Zhao, W., Chung, T., Wang, W., Chang, K., & Peng, N. (2023). Mitigating Bias for Question Answering Models by Tracking Bias Influence. ArXiv. /abs/2310.08795