Introduction
Analyzing question-answering capabilities of LLMs is important because building applications with language models involves many moving parts. Evaluation and testing are both critical when thinking about deploying Large Language Model (LLM) applications. So, a crucial question arises:
How effective is our current evaluation process in keeping up with the ever-evolving landscape of language models?
You’re not alone if you’ve been wondering about this. The AI and language processing world is always changing, with new models and tricks popping up all the time. We need to make sure our testing methods are as cutting-edge as the tech itself.

In this blog post, we take on this challenge by enhancing the QA evaluation capabilities using LangTest library. We will explore about evaluation methods that LangTest offers to address the complexities of evaluating Question Answering (QA) tasks. Furthermore, we’ll perform robustness testing for Large Language Models and evaluate them using various evaluation metrics, including Embedding Distance Metrics, String Distance Metrics, and QAEvalChain approach inspired by the LangChain library. These additions significantly enrich our toolkit for comparing embeddings and strings, providing users with a comprehensive set of tools to conduct QA evaluations finely tailored to their specific use cases.
Large Language Models (LLMs) in Question Answering
Large Language Models (LLMs) have revolutionized the field of Question Answering (QA). QA models play a crucial role in retrieving answers from text, particularly in document search. Some QA models can generate answers independently without requiring additional context.

LLMs have demonstrated unprecedented performance in various QA tasks, making them invaluable tools for a wide range of applications, from information retrieval to natural language understanding. However, alongside their remarkable capabilities, there are inherent challenges in evaluating the performance of LLMs in the context of QA. This section explores the importance of assessing LLMs in QA and delves into the associated evaluation challenges.
Why Assessing LLMs in QA is Crucial
LLMs, while powerful, are not infallible. They can sometimes produce inaccurate, biased, or contextually inappropriate answers, especially when faced with complex questions or diverse data sources. Consider a QA system designed to provide medical advice. The accuracy of its responses is paramount, as incorrect information can have serious consequences. QA evaluation plays a critical role in ensuring the reliability and safety of such systems.
Furthermore, LLMs must continuously adapt to the evolving landscape of language models, with new models and techniques emerging regularly. This raises questions about how well current QA evaluation methods can keep pace with these advancements. A robust evaluation process is vital for assessing the compatibility of LLMs with the latest developments, ensuring their continued effectiveness and relevance in this dynamic field.
How LangTest Addresses the Challenge
LangTest helps in evaluating LLM models with respect to various benchmark datasets and a wide variety of tests, including robustness, bias, accuracy, and fairness, to ensure the delivery of safe and effective models. By addressing these aspects, we can enhance the trustworthiness and utility of LLMs in various applications.
Robustness testing of LLMs with LangTest
Robustness testing aims to evaluate the ability of a model to maintain consistent performance when faced with various perturbations or modifications in the input data. For LLMs, this involves understanding how changes in capitalization, punctuation, typos, contractions, and contextual information affect their prediction performance.
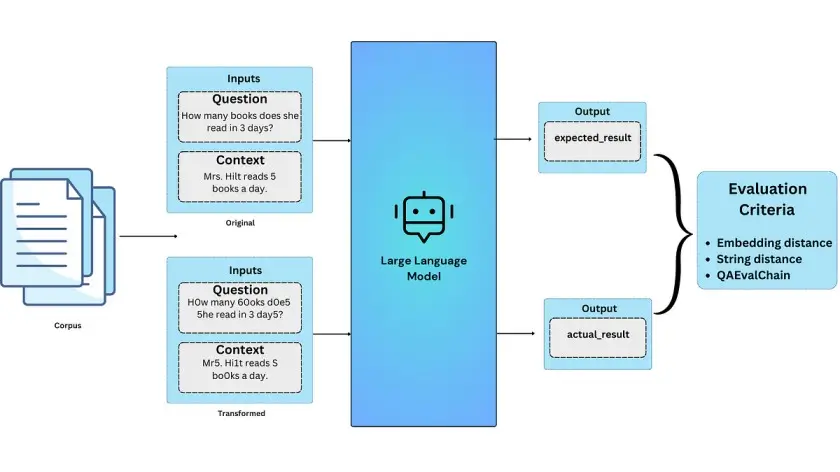
LangTest offers a versatile set of evaluation methods to address the complexities of evaluating Question Answering (QA) tasks. These methods include Embedding Distance Metrics for comparing embeddings, String Distance Metrics for measuring string similarity, and the default QAEvalChain approach inspired by the LangChain library. These evaluation tools are pivotal in ensuring the effectiveness and reliability of Large Language Models in the ever-evolving landscape of language technology.
Now, we will explore these approaches and learn how to use them side by side with LangTest for effective evaluation of Question Answering (QA) tasks.
Initial Setup
# Install required packages
!pip install "langtest[openai,transformers]"==1.7.0
# Import necessary libraries
import os
# Set your OpenAI API key
os.environ["OPENAI_API_KEY"] = ""
#Import Harness from the LangTest library
from langtest import Harness
# Define the model and data source
model={"model": "text-davinci-003","hub":"openai"}
data={"data_source" :"CommonsenseQA-test-tiny"}
# Create a Harness object
harness = Harness(task="question-answering", model=model, data=data)
In this setup, we’ll be using text-davinci-003 from OpenAI for question-answering (QA) tasks. The dataset of choice is “CommonsenseQA-test-tiny”, a truncated version of “CommonsenseQA” This dataset challenges models with a diverse range of commonsense knowledge questions. We’ll evaluate the model using embedding distance metrics, string distance metrics, and QAEvalChain, to determine the effectiveness of each evaluation method.
Embedding Distance Metrics
Embedding distance metrics are mathematical measures used to determine how similar or dissimilar data points are when they’re transformed into numerical vectors within a vector space. They play a vital role in various applications by helping us quantify the relationships between data points.
langtest offers a range of embedding models from different hubs, with two default models preconfigured:

With Langtest, you have the flexibility to choose your preferred embedding model and hub. This allows you to create embeddings for your expected_result and actual_result.
These embeddings can then be compared using various distance metrics defined in the configuration. Langtest Library supports the following distance metrics for comparing text embeddings:
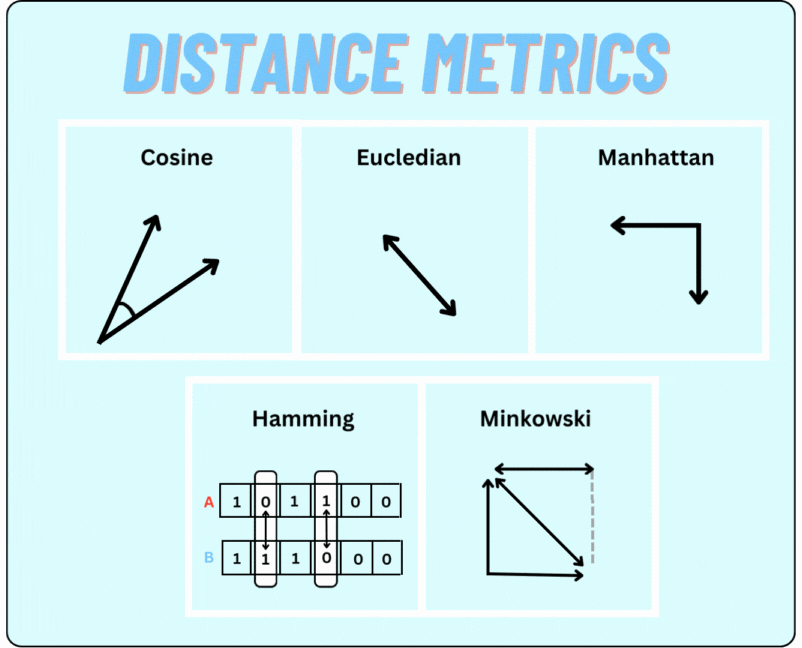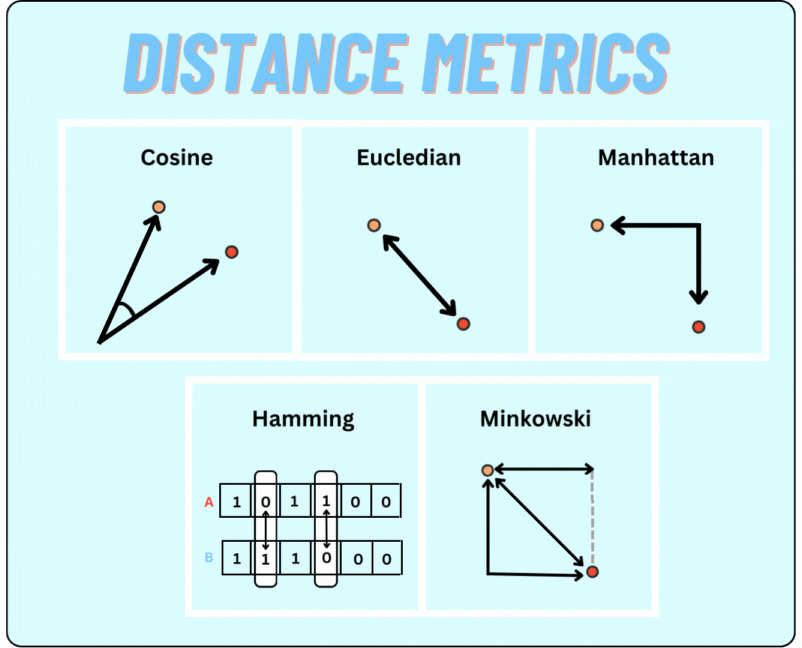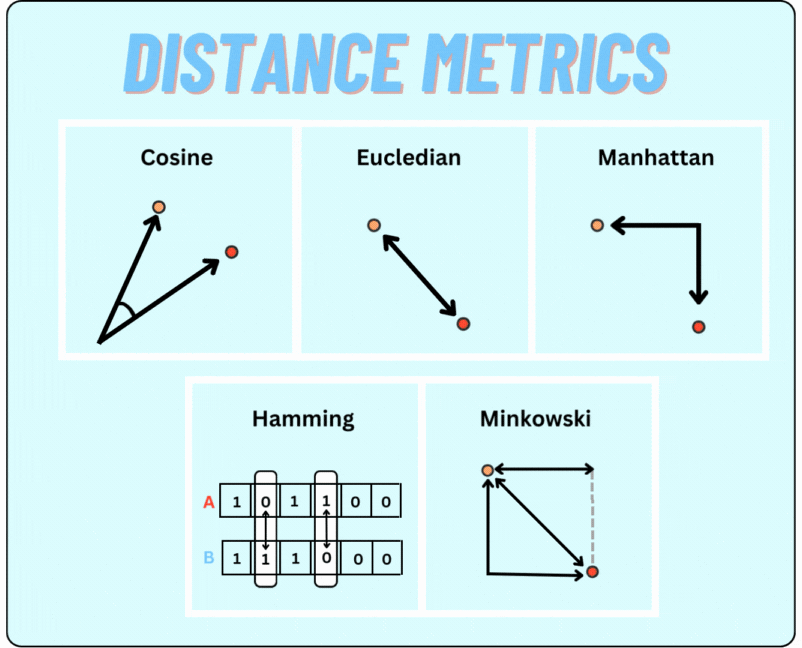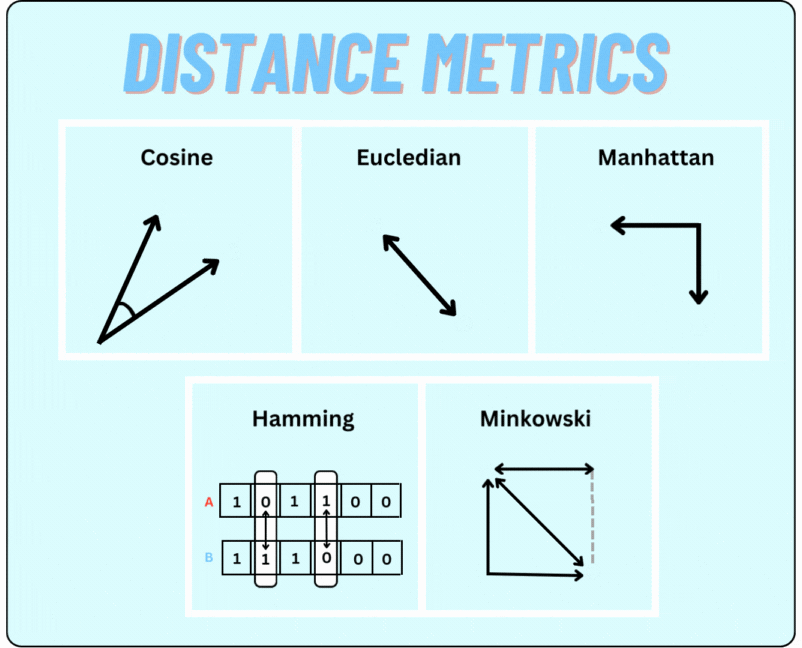
Configure Harness
harness.configure(
{
"evaluation": {"metric":"embedding_distance","distance":"cosine","threshold":0.9},
"embeddings":{"model":"text-embedding-ada-002","hub":"openai"},
# Note: To switch to the Hugging Face model, change the "hub" to "huggingface" and set the "model" to the desired Hugging Face embedding model.
'tests': {'defaults': {'min_pass_rate': 0.65},
'robustness': {'add_ocr_typo': {'min_pass_rate': 0.66},
'dyslexia_word_swap':{'min_pass_rate': 0.60}
}
}
}
)
In our Harness configuration, we’ve set up the embedding_distance metric with a cosine distance threshold of 0.9 to assess the model’s performance. Additionally, we’re using the text-embedding-ada-002 model from OpenAI to obtain embeddings for the expected_result and actual_result, enhancing the evaluation process. We are also applying robustness tests, including add_ocr_typo and dyslexia_word_swap, to evaluate the model’s language understanding and robustness comprehensively.
Generate, run and get Generated results for the test cases
harness.generate().run().generated_results()
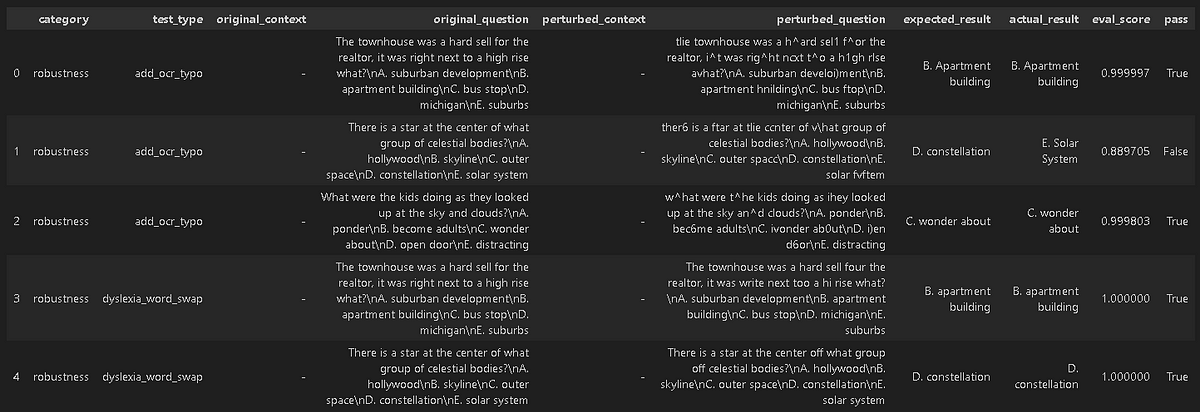
Note: If the above evaluation metric, threshold value, or embeddings model does not work for your use case, you can easily customize the configuration. Simply adjust the configuration parameters to suit your specific needs, and then call the `.generated_results()` method with the updated configuration.
String Distance Metrics
Langtest provides a collection of string distance metrics designed to quantify the similarity or dissimilarity between two strings. These metrics are useful in various applications where string comparison is needed. The available string distance metrics include:

Users can specify the desired string distance metric for comparing the expected_result and actual_result.
Note: returned scores are distances, meaning lower values are typically considered “better” and indicate greater similarity between the strings. The distances calculated are normalized to a range between 0.0 (indicating a perfect match) and 1.0 (indicating no similarity).
harness.configure(
{
"evaluation": {"metric":"string_distance","distance":"jaro","threshold":0.1},
'tests': {'defaults': {'min_pass_rate': 0.65},
'robustness': {'add_ocr_typo': {'min_pass_rate': 0.66},
'dyslexia_word_swap':{'min_pass_rate': 0.60}
}
}
}
)
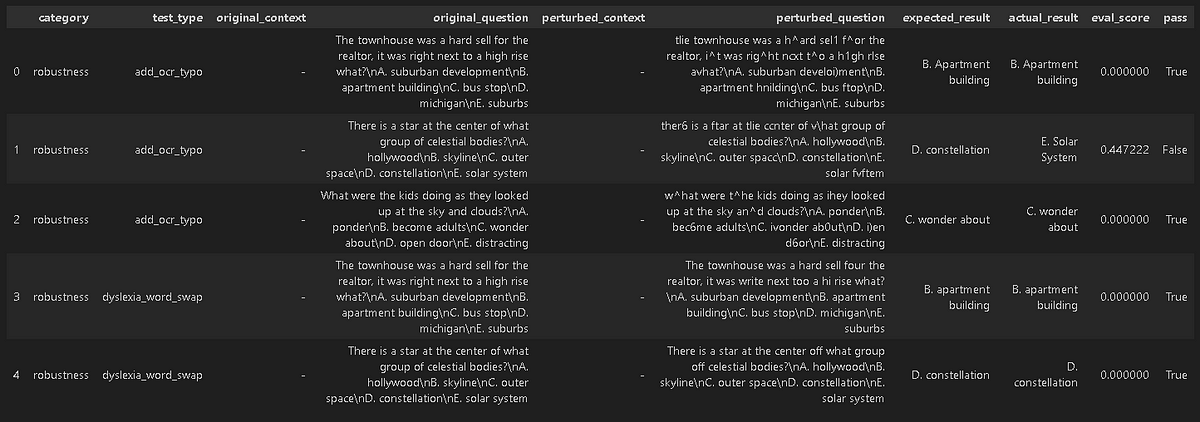
#Generated Results
harness.generated_results()
Now, we will once more configure the harness, setting up the string_distance metric with the Jaro distance and a 0.1 threshold. Notably, this configuration does not involve the use of embeddings, unlike our previous setup. The remaining aspects of the configuration remain consistent with our previous configuration.
Evaluating with QAEvalChain
In LangTest, we utilize the capabilities of the QAEvalChain from the LangChain library to evaluate Question Answering (QA) tasks. This approach leverages Large Language Models (LLMs) as metrics to assess the performance of QA models.
The QAEvalChain simplifies the evaluation process as it takes in key inputs such as the original question, the expected answer (ground truth), and the predicted answer. After rigorous evaluation, it provides outcome labels, marking the prediction as either “CORRECT” or “INCORRECT” when compared to the expected answer.
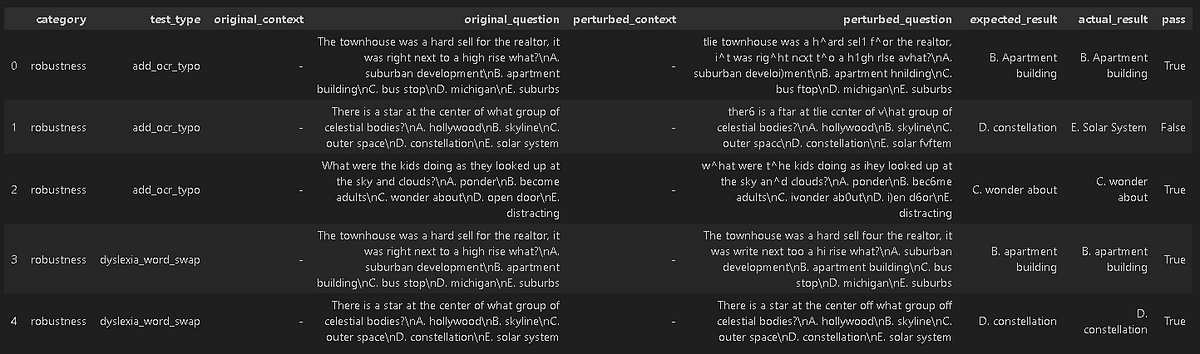
Here’s how it operates in LangTest for robustness testing:
- The evaluation process is conducted on the provided data, assessing the original question and the expected results (ground truth), as well as the perturbed question and the actual results.
- The outcome of the evaluation process determines whether the actual results align with the expected results (ground truth).
While the default approach in LangTest involves using the QAEvalChain for QA evaluation, If you prefer to use specific evaluation metrics like String Distance Metrics or Embedding Distance Metrics, you can easily configure them in the LangTest, just like we did above.
# Evaluating with QAEvalChain
harness.configure(
{
'tests': {'defaults': {'min_pass_rate': 0.65},
'robustness': {'add_ocr_typo': {'min_pass_rate': 0.66},
'dyslexia_word_swap':{'min_pass_rate': 0.60}
}
}
}
)
#Generated Results
harness.generated_results()
Conclusion
In conclusion, the ever-evolving landscape of language models demands an equally dynamic approach to evaluation and testing. Large Language Models (LLMs) are powerful tools in Question Answering (QA), but they are not without their challenges. LangTest addresses these challenges by offering a versatile set of evaluation methods, including Embedding Distance Metrics, String Distance Metrics, and the QAEvalChain approach. These tools ensure the reliability and effectiveness of LLMs in the face of new models and techniques. With LangTest, users can fine-tune their QA evaluations to suit their specific use cases, ensuring the continued relevance of LLMs in the rapidly changing world of language technology.
References
- LangTest Homepage: Visit the official LangTest homepage to explore the platform and its features.
- LangTest Documentation: For detailed guidance on how to use LangTest, refer to the LangTest documentation.
- Full Notebook with Code: Access the full notebook containing all the necessary code to follow the instructions provided in this blog post.
- QAEvalChain from the LangChain library.
- Healthcare LLM
FAQ
How does LangTest evaluate question-answering performance in LLMs?
LangTest uses a two-layer evaluation method: first it checks if the perturbed question yields the same answer as the original; if not, it uses embedding or string distance metrics (e.g., cosine similarity, Levenshtein) to verify semantic equivalence.
What types of perturbations are used to test LLM robustness in QA tasks?
Common perturbations include changes in casing, formatting, synonym substitutions, added typos, and abbreviations; these test whether models maintain accuracy under real-world input variations.
Which distance metrics does LangTest support for QA evaluation?
It supports embedding-distance metrics (cosine, Euclidean, Manhattan, Chebyshev, Hamming) and string-distance metrics (Jaro, Jaro-Winkler, Hamming, Levenshtein, Damerau-Levenshtein, Indel).
What LLMs show high robustness on QA benchmarks like OpenBookQA?
Models like GPT‑3.5‑turbo‑instruct, text‑davinci‑003, Intel/neural-chat‑7b, and GPT‑4‑1106‑preview perform strongly across robustness tests, while others like J2‑jumbo and Mistral‑7B struggle.
How can QA test reports guide model improvement?
Detailed QA test reports highlight failure types, enabling developers to fine-tune models, apply data augmentation, or adjust prompting strategies to improve performance under input variability.