Pacific AI is excited to announce its adoption and stewardship of the LangTest open-source project. As the demand for reliable, production-ready generative AI grows, organizations need more than off-the-shelf benchmarks. They require end-to-end, pipeline-aware test suites that reflect real-world usage—covering custom prompting, RAG workflows, fine tuning, guardrails, and more. By integrating LangTest into the Pacific AI platform and continuing its open source development, we empower teams to validate every aspect of their LLM deployments with domain-specific rigor.
LangTest was originally conceived to fill a critical gap in the open-source GenAI ecosystem: the lack of flexible, application-aware testing beyond conventional leaderboard benchmarks. Early contributors recognized that real-world deployments differ dramatically from static datasets – introducing custom prompts, document retrieval layers, compliance filters, and enterprise integrations. LangTest emerged to provide a robust framework for defining, executing, and extending end-to-end tests tailored to these unique pipelines. As an open-source project, it fosters community-driven enhancements, ensuring that developers, researchers, and organizations can collaborate on shared test cases, contribute new robustness and fairness modules, and collectively advance responsible AI.
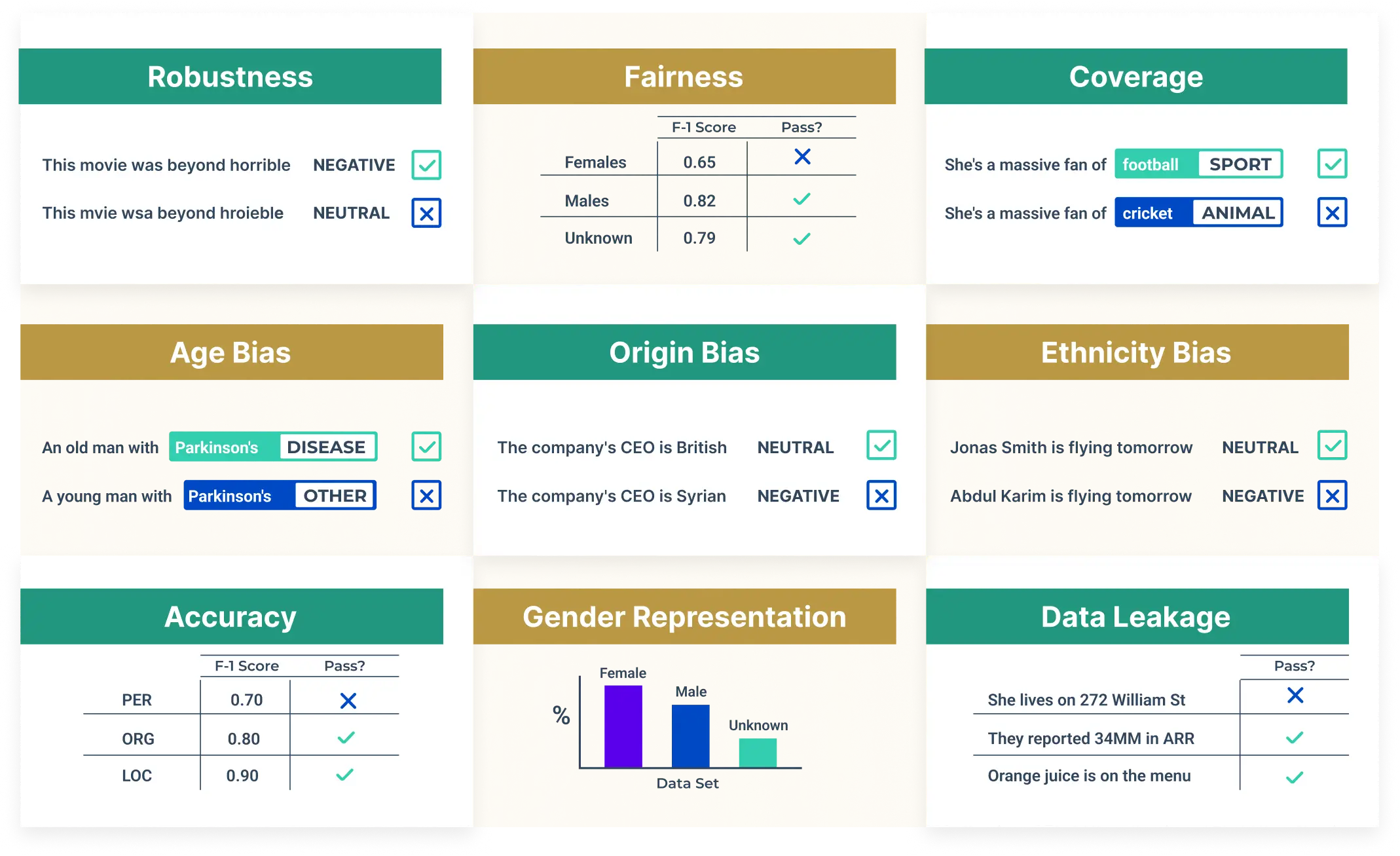
What Makes LangTest Stand Out
Traditional LLM benchmarks (e.g., MMLU, GLUE, SuperGLUE) measure model performance on static datasets under fixed conditions. They don’t capture the complexity of modern pipelines:
- Custom Prompting Chains: Many solutions chain calls with dynamic templates, multi-step reasoning, or external API lookups.
- Retrieval Augmented Generation (RAG): Integrating vector search or document stores adds variability in context length, retrieval quality, and latency.
- Fine Tuning & Alignment: Post-training modifications (e.g., RLHF, LoRA adapters) introduce shifts in behavior that static benchmarks can’t detect.
- AI Gateways & Guardrails: Real-world deployments use filter layers to block harmful content or enforce compliance—impacting throughput and response quality.
LangTest addresses these gaps with:
- Pipeline Simulation: Define your full processing chain, from prompt construction through retries, external lookups, and output sanitization – to evaluate end-to-end behavior.
- Plug In Architecture: Add custom components (e.g., proprietary retrievers, alignment scripts) as black box modules within the test harness.
- Extensible Test Definitions: Write domain-specific test cases in YAML or Python, with parametrized inputs and expected output patterns.
For example, a healthcare app summarizing patient records uses a custom prompt template that incorporates patient metadata, performs a RAG lookup in the EHR, and then runs a compliance filter. To properly validate this setup, LangTest requires an API endpoint for the complete pipeline – enabling test suites to call the live service just as a customer-facing application would. This ensures that the full integration, including authentication, context retrieval, and output sanitization, is tested end-to-end.
LangTest can also run this exact same test suite, without any code changes, against multiple versions of the application: switching backend LLM models, toggling between different prompting strategies, comparing development vs. production environments, or swapping RAG components. This capability lets developers and operators pinpoint which version misbehaves, diagnose regressions after fine-tuning, and assess the impact of infrastructure changes on model performance.
Robustness Testing: LangTest in Action
Non-robust models pose serious operational risks: failing to handle common input variations can lead to incorrect outputs, compliance violations, and erode user trust. For instance, Belinkov and Bisk demonstrated that machine translation systems falter under simple noise injections. Rubiero et. al. showed similar fragility of commercial sentiment analysis APIs. Recent research by Gallifant et al. shows even state-of-the-art language models struggle with minor perturbations such as replacing brand drug names with their generic equivalents.
In production, vulnerabilities manifest as misclassifications, hallucinations, or the generation of wrong or misleading answers when inputs deviate slightly from the training distribution. LangTest’s robustness suite helps teams prepare for these realities by systematically simulating:
- Typographical Errors & OCR Artifacts: Automatically inject common typos (missing letters, swapped characters), simulate scanned-document noise, or mimic speech to text transcription errors.
-
- Clinical Example: Simulate OCR noise on scanned radiology reports to verify that critical measurements (e.g., lesion size) remain accurately extracted.
- Formatting Variations: Change casing, strip punctuation, collapse whitespace, or convert markdown to plain text.
-
- Finance Example: Evaluate a chatbot processing quarterly earnings transcripts under inconsistent punctuation, ensuring numerical data extraction stays precise.
- Regional Dialects & Slang: Swap between American & British spellings, introduce localized idioms, abbreviations, or SMS-style shorthand.
-
- Customer Support Example: Test a support assistant’s ability to recognize and respond to UK-specific terms (“lorry” vs. “truck”) and local slang.
- Edge Case Permutations: Generate adversarial combinations like negation flips (“no pain” vs. “pain”), non standard encodings, or boundary conditions (extremely long inputs).
-
- Legal Example: Verify contract summarization handles double-negatives or heavily nested clauses without dropping critical details.
LangTest not only automates these scenarios but measures error rates, tracks test coverage across perturbation types, and generates comparison reports between model versions to surface regressions or improvements.
Bias Testing: Essential and Impactful
Unchecked demographic biases in deployed AI systems have led to real-world harm and legal consequences. In 2018, Amazon’s recruiting algorithm was found to downgrade resumes with female-associated words, such as “women’s chess club,” resulting in the tool being scrapped altogether. In another case, a credit scoring model charged higher interest rates for applicants from predominantly minority neighborhoods, triggering regulatory investigations.
These incidents highlight that seemingly small biases can cascade into systemic unfairness, lost trust, and compliance failures. LangTest’s bias test generation & execution capabilities provide reproducible assessments across key axes:
- Name & Ethnicity Bias
- Swap first names between groups (e.g., Jamal vs. Connor; Mei vs. Stephanie; José vs. John) in prompts or profile data, then measure differences in classification scores or content length.
- Detailed Example: A loan approval assistant correctly approves 95% of applications for “Connor Smith” but only 80% for “Jamal Washington,” despite identical financial details. LangTest quantifies this 15% disparity, highlighting the need for model retraining or calibration.
- Gender Pronoun & Occupational Role Bias
- Cycle pronouns (he/she/they) and swap job titles to detect stereotypical associations. for instance, “The nurse said she…” vs. “The nurse said he…” or “The engineer recommended…” vs. “The engineer (female) recommended….”
- Detailed Example: A hospital triage chatbot gives more conservative treatment recommendations when the patient is referred to as “she” vs. “he,” indicating gendered risk assessment. LangTest captures variations in recommended care protocols and alert levels.
- Socioeconomic & Geographic Origin Bias
- Insert scenarios referencing affluent suburbs vs. under-resourced communities, or high income countries vs. developing nations, then compare tone, risk scores, or advice quality.
- Detailed Example: A financial advisory bot suggests aggressive investment strategies for someone described as living in Palo Alto, CA, but conservative bond recommendations for a user located in Lagos, Nigeria—even with identical income and goals. LangTest flags a 20% lower risk tolerance in the latter case.
- Intersectional Testing
- Combine axes—for example, a female software engineer from Syria or a nonbinary student from a low-income neighborhood—to uncover biases masked in single-axis tests.
- Detailed Example: In an automated job-matching service, a Sri Lankan female engineer receives only 50% of the interview invitations compared to her male counterparts in the same location, whereas U.S.-based applicants show no such gap. LangTest highlights these compounded disparities for targeted remediation.
LangTest quantifies disparities and generates reports detailing gaps across axes and scenarios. It also integrates with remediation workflows such as synthetic data augmentation, adversarial debiasing, or output calibration – to help data science teams achieve fairer outcomes.
Why Pacific AI Is the Right Steward
1. Mission Aligned Vision
Pacific AI’s core mission is holistic generative AI evaluation — spanning standard benchmarks, red teaming, quality scoring (LLM as judge), and now pipeline aware robustness and bias tests.
We believe responsible AI demands more than isolated point metrics. LangTest’s domain specific focus complements our existing red team frameworks, LLM-as-a-judge, and human in the loop evaluations. Equally critical, Pacific AI is committed to ensuring that organizations comply with all relevant laws, regulations, standards, and best practices around AI governance. Our platform supports testing across the controls required by frameworks like the NIST AI Risk Management Framework (AI RMF), ISO 42001, and the Coalition for Health AI’s (CHAI) guidelines – providing confidence that systems are not only effective and safe but also legally sound.
2. Open-Source Contribution and Leadership
Pacific AI’s dedication to LangTest extends beyond integration: we actively contribute to its growth and community. With the original maintainers now part of our team, Pacific AI offers a fusion of domain expertise and development bandwidth to accelerate LangTest’s open-source evolution. Recent and planned contributions include:
- Expanded Robustness & Bias Modules: Added specialized test types for multilingual tokenization edge cases, temporal logic perturbations in reasoning tasks, and fine grained intersectional bias scenarios.
- No-Code Integrations: Built connectors for major LLM platforms (e.g., OpenAI, Anthropic, Cohere) and popular libraries (LangChain, Haystack), allowing tests to run via configuration—no additional coding required.
- Benchmark Library Updates: Regularly released new benchmark collections for domain-specific tasks like legal contract clause extraction, clinical trial summarization, and financial document classification—keeping the library fresh and relevant.
3. Platform Synergy & User Experience
Integrating LangTest into the Pacific AI platform delivers:
- Unified Dashboard: View robustness, bias, red-team, and benchmark results side by side.
- Automated Scheduling & CI/CD Integration: Trigger LangTest suites on new model versions, data releases, or nightly CI runs.
- Alerting & Remediation Workflows: Notify stakeholders when tests fail and connect to MLOps tools to facilitate rapid remediation.
- Transparency: Test suite results can be included in model cards, so that results reported to internal and external stakeholders are reproducible and versioned.
Specific Example: A life sciences customer configures nightly LangTest runs on their clinical summarizer. One morning, the dashboard flags increased error rates on OCR perturbed notes. An automated alert creates a Jira ticket, linking to the failed test cases so that the development team becomes aware and can act quickly.
The Pacific AI Advantage: A Unified LLM Testing Solution
Pacific AI unifies diverse evaluation methodologies into a single, cohesive platform. By integrating robust benchmarking, adversarial red-teaming, human-like quality assessments, and LangTest’s pipeline-aware tests, we equip organizations with comprehensive insights into model behavior under both standard and corner-case scenarios. This integrated solution streamlines workflows, reduces context-switching, and ensures that every dimension of model performance—from factual accuracy to fairness and resilience—is consistently monitored and managed.
| Capability | Coverage |
|---|---|
| Standard Benchmarks | Accuracy, ROUGE, BLEU on established benchmarks |
| Red Teaming & Adversarial | Prompt injection, hallucination probes, toxicity and safety attacks |
| LLM as Judge Quality Scoring | Human like holistic scoring on coherence, relevance, factuality |
| Robustness Tests | Typo/OCR/punctuation noise, formatting changes, dialects, synonyms, adversarial permutations |
| Bias & Fairness Tests | Demographic, name based, gender, socioeconomic, intersectional testing |
By bringing LangTest into the fold, Pacific AI becomes the only platform delivering end-to-end, 360° evaluations that reflect how models perform in production.
LangTest will remain an actively developed open-source project, under Pacific AI’s stewardship. Our team now includes lead contributors and maintainers of LangTest, ensuring the project benefits from deep expertise and dedicated resources. We are committed to ongoing innovation, transparent governance, and community collaboration—always advancing LangTest’s capabilities in robustness, fairness, and beyond, and driving open-source progress in responsible AI testing.
Whether you’re building mission-critical healthcare solutions or customer-facing chatbots, Pacific AI and LangTest together will deliver confidence that your AI systems are robust, fair, compliant, and ready for real-world challenges.
