










Guardian: Continuous
Red Teaming in Production
The Guardian Agent runs Pacific AI’s full test library, bias, safety, robustness, clinical task performance, and regulatory readiness, against your production AI systems, continuously. Detects drift that observability platforms cannot see. Throttled to near-zero impact on production load.

A test suite that catches bias before release does not catch bias that creeps in afterward. A regulatory readiness check that passes at deployment does not catch a model that drifts out of compliance two months later. A safety benchmark a clinical AI passed in QA does not catch a rare but critical scenario the model has never been tested on in the field.
Guardian runs Pacific AI’s full test library, bias, safety, robustness, clinical task performance, regulatory readiness, and adversarial security, against your production deployment, on a schedule you set. Same suites, same scoring, same baselines. Continuously, throttled, complementary to your existing observability stack.



Science2People automates high-stakes science communication, using Generative AI to translate complex research into accurate, accessible content. The Guardian Agent performs independent red teaming – identifying “hidden middle” failures, monitoring for drift, and benchmarking against frontier models to ensure every output is trustworthy, unbiased, and compelling.
What Guardian is not
market is well served. Guardian is built to do what they cannot.
Observability Platforms
Datadog, Splunk, OpenTelemetry, cloud-native LLM observability
Log every call to your AI system, request, response, latency, token counts, errors. They do this well, and Pacific AI does not duplicate them.
Guardian does not log production traffic. Guardian sends test traffic.
AI Gateways & Guardrails
NeMo Guardrails, Llama Guard, cloud content-moderation APIs, proxy-based gateways
Inspect each user request and each model response live, blocking outputs that violate rules you configure. They do this well, and Pacific AI does not duplicate them.
Guardian does not sit in the path of production traffic. Guardian sends scheduled probes alongside it.
Classic Monitoring
New Relic, Dynatrace, AppDynamics, uptime & APM tools
Tell you whether the system is up and how it is performing. They do this well, and Pacific AI does not duplicate them.
Guardian does not measure system health. Guardian measures AI behavior.
What all of these tools share is a structural limit: they only see what users send.
Bias gapsA user-traffic monitor cannot test for bias against demographic groups your users do not represent in proportion to the testing your compliance program requires.
Unknown jailbreaksA guardrails library that blocks one observed jailbreak does not test whether the model would respond unsafely to a thousand others no user has yet attempted.
Rare-but-critical failuresAn observability platform that logs every error this week cannot tell you whether the chatbot would correctly handle a rare medical emergency a patient might bring up tomorrow.
How Guardian runs in production
Worked Example:
3,600-case bias suite at one call every 5 seconds
3,600Cases
5Seconds per call
5 hoursFull Suite
Schedules Per Suite, Per Environment
Safety suite hourly against staging. Bias suite daily against production. Full regulatory readiness suite weekly with the most recent Policy Suite refresh. Configure once in Governor; Guardian executes.
Drift Detection vs Release-Time Baseline
Every probe is scored against the same baselines the system passed at release time. If a metric drops below the threshold Gatekeeper passed it on, Guardian flags the regression by metric, suite, environment, and model version.
Integration Is Zero on the AI Side
The agent calls your AI endpoints the same way any other client does. No SDK to embed, no proxy to install, no traffic to redirect. Your existing observability platform sees Guardian’s traffic as just another API consumer.
What you see, every day
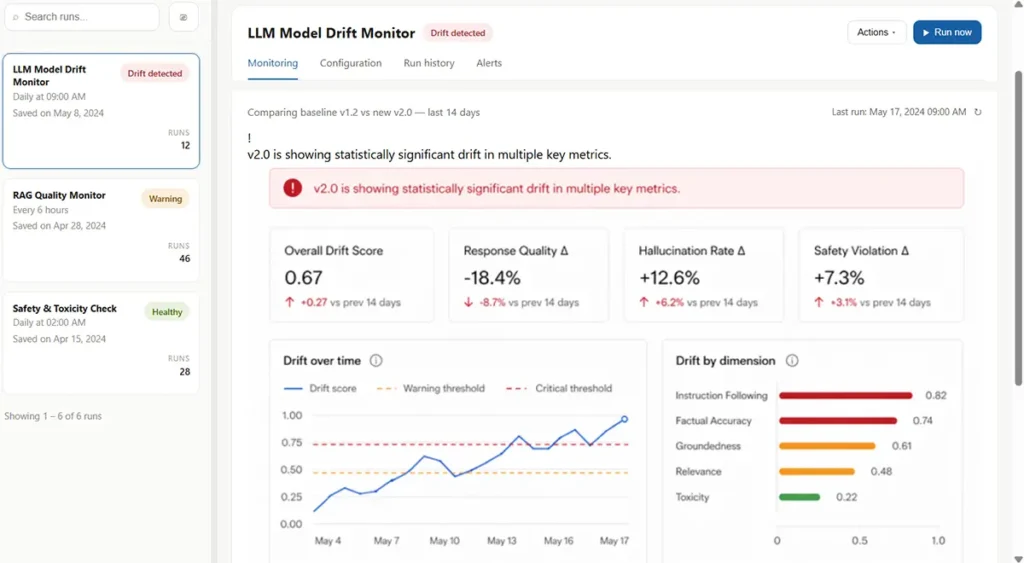
What Guardian tests for
Clinical Task Performance
MedHELM tasks (5 categories, 22 subcategories, 121 clinical tasks, 35 benchmarks; with Stanford CRFM) against production. Detect when a model that performed well on differential diagnosis at release time has drifted on a specific subcategory.
Demographic & Cognitive Bias
Perturbation testing across protected categories (race, ethnicity, gender, age, language, insurance status, disability) and across medical cognitive biases (anchoring, confirmation, availability, premature closure).
Safety & Clinical Correctness
Clinical case libraries, drug-interaction checks, dose-range validation, red-flag-symptom detection, edge cases (anaphylaxis presenting atypically, suicidal ideation in a routine check-in).
Adversarial Security
Prompt injection, jailbreaking, system-prompt extraction, training-data extraction, RAG poisoning. The same Pacific AI red-team library (50+ attack categories) running against production endpoints, throttled.
Regulatory Readiness
HHS HTI-1, ACA 1557, FDA 2024-D-4488, the state AI laws (CA AB 489, NV AB 406, UT HB 452, IL HB 1806, TX SB 1188, TX HB 149, Colorado SB24-205), the EU AI Act, NIST AI RMF, ISO/IEC 42001. When the Policy Suite refreshes quarterly, Guardian re-runs production deployments automatically.
Real drift detection: what observability cannot see
Bias Regression After a Model Swap
- TriggerA health-system chatbot upgrades from one frontier LLM version to a newer one.
- ObservedUser traffic looks normal: same volumes, same latencies, same error rates.
- GuardianDaily bias suite finds fairness on insurance-status perturbation has dropped from 0.81 to 0.67. Model now responds differently to “I have Medicaid” vs “I have private insurance.”
- OutcomeTeam alerted within hours; rollback triggered before any patient is affected.
Regulatory Readiness Regression After a Policy Suite Update
- TriggerA new state AI law (TX HB 149) takes effect with disclosure requirements for AI use in clinical contexts.
- ObservedProduction traffic logs show nothing unusual; no patient happened to invoke the failing case yet.
- GuardianPolicy Suite refresh adds new TX HB 149 cases. Guardian runs them against production and finds the chatbot fails the disclosure-on-emergency case.
- OutcomeCompliance alerted; model card updated; the fix gets prioritized before exposure.
Clinical Safety Regression After a RAG Corpus Update
- TriggerThe clinical knowledge base behind a RAG-grounded clinical decision support system gets a routine quarterly refresh.
- ObservedThe user-facing system continues to work; latencies are unchanged; observability dashboards are green.
- GuardianClinical edge-case suite, throttled against production, detects degraded response to atypical anaphylaxis presentation. The new corpus deprecated the source the model relied on.
- OutcomeOn-call clinical informaticist is paged before any patient triggers the case.
Regulatory Readiness Regression After a Policy Suite Update
- TriggerTeam updates the guardrail library to handle a new class of prompt injection.
- ObservedProduction traffic looks fine; no users are hitting the new guardrails, because no users are mounting prompt-injection attacks.
- GuardianAdversarial security suite runs the full red-team library against production weekly and finds the new guardrail change broke a previously-blocked jailbreak path.
- OutcomeVulnerability is closed before it is exploited.
Three engines, one production-testing platform
LangTest
Runs Guardian’s fairness, robustness, and accuracy probes against production endpoints. The full library, including the perturbation tests Gatekeeper uses for release gating, executes on Guardian’s throttled schedule, scored against the release-time baseline.
Learn more about LangTest →MedHELM
Provides Guardian’s clinical-task evaluation library. The same 121 clinical tasks across 35 benchmarks (with Stanford CRFM) Gatekeeper benchmarks against at release time run continuously against production, with drift detection on a per-subcategory basis.
Learn more about MedHELM →Red Teaming
Drives Guardian’s adversarial security probes. Pacific AI’s red-team library, 50+ attack categories across three groupings, refreshed continuously, executes against production endpoints on a schedule you set, throttled to near-zero impact.
Learn more about red teaming →Three reasons this is the right
production-testing platform
Purpose-Built for Healthcare
Same MedHELM clinical tasks (Stanford CRFM partnership), healthcare-specific safety categories, medical cognitive bias testing, and federal-and-state healthcare-AI laws Gatekeeper gates releases on, running continuously against production. Most production AI monitoring is general-purpose; Guardian’s tests were designed for clinical AI.
Same Methodology, CI/CD to Production
Pacific AI is the only platform where the test suite that gates a model at release continues to run against the production deployment, same scoring, same thresholds, same baselines, same Policy Suite. Nothing to re-implement. No separate monitoring methodology to maintain.
Continuous, Not One-Time
Production AI drift is continuous; testing has to be too. Guardian schedules per suite, per environment; throttles to bound production load; re-runs against the Policy Suite when it refreshes quarterly; routes findings to the right role in Governor. A model that passed last quarter does not stay passed.
Policy to testing to production in one platform
Production Tests Update Automatically When the Policy Suite Refreshes
When a state AI law takes effect, a framework like FUTURE-AI publishes an update, or CHAI revises its schema, the Policy Suite refreshes with new test cases. Guardian picks up the updated suite on the next scheduled run, against your existing production deployments. No monitoring re-engineering, no compliance ticket to engineering.
Drift Findings Update the Live Status of Risk Register Controls
When a project’s risk analysis required bias monitoring on protected categories as a control, Governor wires that control to Guardian’s bias suite running against production. The control’s status in the risk register reflects the score continuously:
- Passing
- Drifting
- Failing
Your Production Drift Data Never Leaves Your VPC
Guardian’s production probes, drift findings, and any test data containing PHI, PII, or PCI from your production environment never leave your VPC. The Guardian Agent runs inside your AWS or Azure tenant; Pacific AI has no access to monitoring data.
Learn more about Pacific AI’s single-tenant architecture →

We architected the system as modular, specialized agents — each one testable, auditable, and replaceable. That’s how we keep AI reliable at scale.
Get Started
differently. There is nothing to buy, nothing to negotiate, and no implementation project before you can use the platform.
Deploys in Minutes
CloudFormation or Managed Apps, inside your AWS or Azure tenant.
Platform Core $0 Forever
Unlimited users, systems, policies, tests, audit trails. Pay only per AI credit.
Agent-Ready
MCP-native integration with agentic AI systems out of the box.
Build the full AI governance program
12-Week AI Accelerator
Forward Deployed Experts (12 months)
Private LLM Deployment