Papers Review Papers
Holistic Evaluation of Large Language Models: Assessing Robustness, Accuracy, and Toxicity for Real-World Applications
As the adoption of Large Language Models (LLMs) accelerates, their performance evaluation becomes increasingly critical—not just in terms of accuracy but across a broader spectrum of metrics like robustness and toxicity.
A recent paper titled “Holistic Evaluation of Large Language Models”, published by researchers at John Snow Labs, introduces an innovative approach to assessing LLMs. This framework evaluates models comprehensively, offering insights that go beyond traditional metrics.
Key Objectives of the Holistic Evaluation Framework
1. Broadening the Scope of Evaluation Metrics
Traditional metrics like BLEU or ROUGE focus narrowly on accuracy, which is insufficient for real-world applications. The new framework includes:
- Robustness: How well a model handles text perturbations like typos, slang, or casing changes.
- Toxicity: The ability of a model to avoid generating harmful or offensive outputs.
- Accuracy: Traditional metrics still play a role, offering a baseline for comparison.
2. LangTest Toolkit and Leaderboard
A key feature of this framework is the LangTest toolkit, an open-source Python library that enables testing of LLMs for a variety of parameters. Paired with the LangTest Leaderboard, it allows stakeholders to compare models on multiple metrics dynamically.
Evaluation Metrics and Findings
1. Robustness
Robustness tests simulate real-world conditions by introducing minor changes to the input text, such as typos or slang. Models are evaluated based on their ability to maintain accurate predictions under these conditions.
Key Finding: GPT-4 scored highest in robustness, demonstrating resilience against text perturbations. Smaller models like Open Chat 3.5 also performed competitively, highlighting that parameter size isn’t the sole determinant of robustness.
2. Accuracy
Accuracy remains a vital metric, focusing on how well models perform tasks like question answering and summarization.
Key Finding: GPT-4 led in accuracy, while smaller models like Mixtral 8x7B and Neural Chat 7B showed commendable performance relative to their size.
3. Toxicity
Toxicity evaluation is crucial for applications in sensitive domains. This metric assesses whether models generate harmful or offensive content.
Key Finding: Llama 2 7B excelled in avoiding toxic outputs, making it a preferred choice for applications where content sensitivity is paramount.
Implications for Real-World Applications
The framework’s holistic approach is particularly valuable for domain-specific applications like healthcare, legal, and finance. Traditional evaluation metrics often fail to capture the nuances required in these fields, such as compliance with ethical standards or sensitivity to misinformation.
1. Healthcare
Models need to provide accurate, bias-free, and clinically relevant outputs to support medical decision-making. Future iterations of the LangTest toolkit will include domain-specific evaluations tailored for healthcare use cases.
2. Legal and Financial Domains
Applications in legal and financial fields demand a higher degree of accuracy and transparency. The ability to measure robustness and toxicity ensures that LLMs can operate reliably in these high-stakes environments.
Innovations in Evaluation
What sets the LangTest framework apart is its dynamic nature. Unlike static datasets, which become outdated as models evolve, this framework allows continuous updates with new datasets, metrics, and tests. This adaptability ensures that evaluations remain relevant and comprehensive over time.
Additionally, the toolkit supports data augmentation, enabling users to create tailored datasets to address specific weaknesses in model performance.
Looking Ahead
The study’s findings emphasize that no single model excels across all metrics. While GPT-4 dominates in accuracy and robustness, smaller open-source models like Neural Chat 7B provide a cost-effective alternative with respectable performance. Similarly, Llama 2 7B’s excellence in toxicity avoidance suggests that specific models can be optimized for unique applications.
Conclusion
As AI continues to influence diverse industries, ensuring its reliability, safety, and fairness is more critical than ever. The holistic evaluation framework proposed in this paper offers a robust methodology for assessing LLMs across multiple dimensions, paving the way for more informed decisions in model selection.
The LangTest toolkit and leaderboard stand as valuable resources for researchers, developers, and businesses alike, fostering transparency and accountability in AI development.
For more information, explore the LangTest Leaderboard: LangTest Leaderboard.
FAQ
How does the Holistic Evaluation framework assess LLM performance?
The framework—using LangTest—measures performance across robustness, accuracy, and toxicity, enabling evaluation under real-world conditions by including tests for adversarial prompts, correctness, and harmful content.
Which LLMs perform best on robustness and toxicity in the study?
GPT‑4 tops both robustness and accuracy tests, Llama 2 leads toxicity evaluation, while Mixtral 8x7B and certain open‑source models (OpenChat 3.5, NeuralChat 7B) perform well across all three dimensions.
What is LangTest and how does it support LLM evaluation?
LangTest is an open-source Python toolkit offering 60+ tests—covering robustness, fairness, toxicity, accuracy, and more—to comprehensively evaluate LLMs and NLP models for real-world applications.
Why is a holistic evaluation necessary beyond accuracy metrics?
Accuracy alone misses critical issues: robustness ensures models withstand noisy or adversarial inputs, and toxicity checks prevent harmful outputs. Holistic evaluation highlights trade-offs between these dimensions.
How can developers use evaluation results to improve LLM deployment?
Developers can consult the LangTest leaderboard to compare model strengths, select models suited to specific use cases, identify weaknesses (e.g., toxicity), and guide fine-tuning or safety interventions.

LangTest: A comprehensive evaluation library for custom LLM and NLP models
Introduction of LangTest, an open-source Python toolkit for evaluating LLMs and NLP models 2024
The use of natural language processing (NLP) models, including the more recent large language models (LLM) in real-world applications obtained relevant success in the past years. To measure the performance of these systems, traditional performance metrics such as accuracy, precision, recall, and f1-score are used. Although it is important to measure the performance of the models in those terms, natural language often requires an holistic evaluation that consider other important aspects such as robustness, bias, accuracy, toxicity, fairness, safety, efficiency, clinical relevance, security, representation, disinformation, political orientation, sensitivity, factuality, legal concerns, and vulnerabilities.
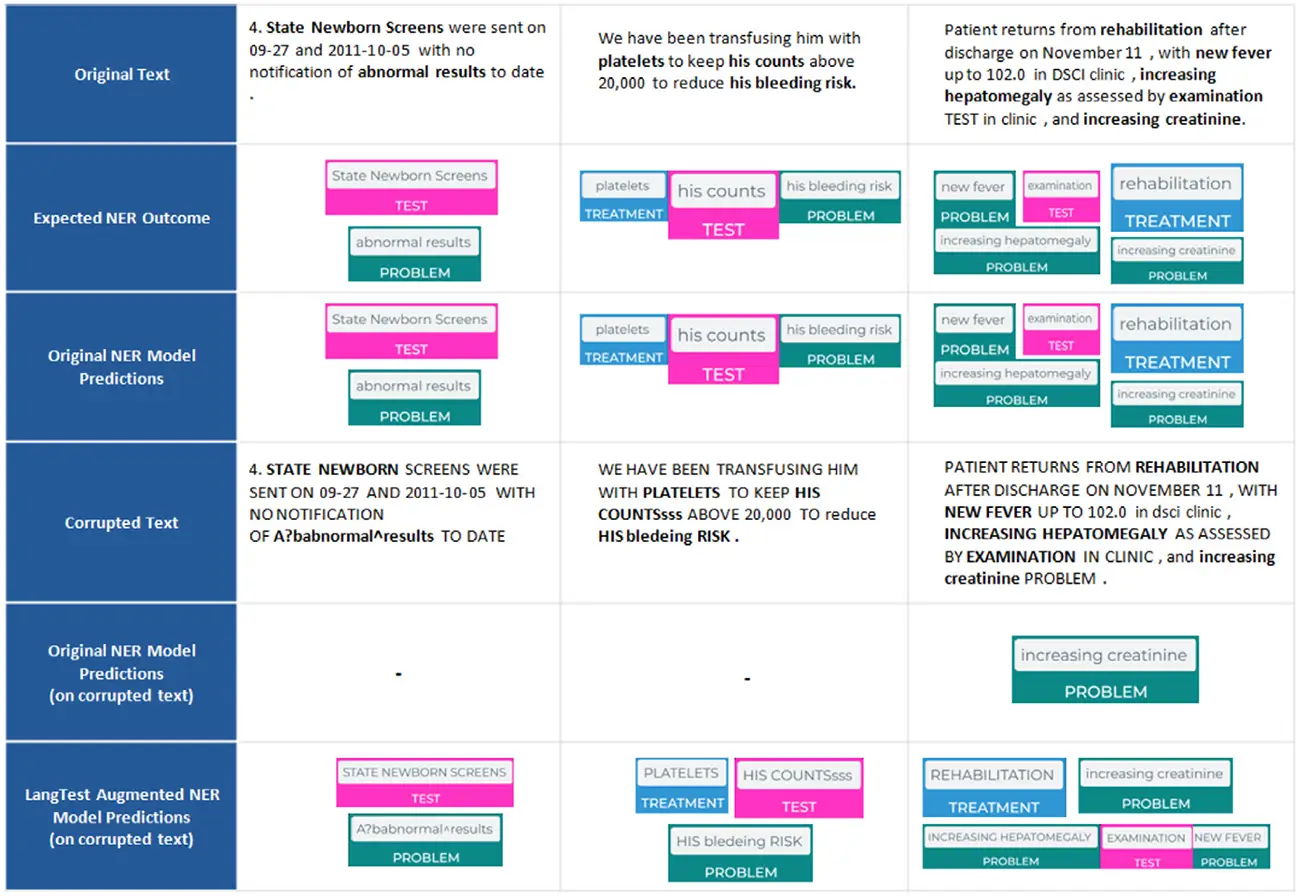
To address the gap, we introduce LangTest, an open source Python toolkit, aimed at reshaping the evaluation of LLMs and NLP models in real-world applications. The project aims to empower data scientists, enabling them to meet high standards in the ever-evolving landscape of AI model development. Specifically, it provides a comprehensive suite of more than 60 test types, ensuring a more comprehensive understanding of a model’s behavior and responsible AI use. In this experiment, a Named Entity Recognition (NER) clinical model showed significant improvement in its capabilities to identify clinical entities in text after applying data augmentation for robustness.
FAQ
What is LangTest and how does it support LLM evaluation?
LangTest is an open-source Python toolkit for evaluating LLMs and NLP models using over 60 test types—including accuracy, robustness, bias, fairness, and toxicity—through simple one‑line code, compatible with major frameworks.
Can LangTest assess models beyond text generation?
Yes. It supports a variety of NLP tasks—such as named entity recognition, translation, classification—and can integrate with models across Spark NLP, Hugging Face, OpenAI, Cohere, and Azure APIs.
What makes LangTest different from other evaluation tools?
Unlike traditional metrics like BLEU or F1, LangTest provides a holistic evaluation—covering robustness, bias, representation, fairness, safety, and more—within a unified, extensible framework.
How does LangTest handle robustness testing of LLMs?
It generates perturbations—such as typos, rephrasing, or casing changes—to test model resilience against adversarial inputs, and provides pass/fail metrics using LLM-based or string-distance evaluation.
What production features does LangTest provide for model comparison and governance?
LangTest offers benchmarking and leaderboard support, multi-model and multi-dataset evaluation, data augmentation, Prometheus eval integration, drug-name swapping, and safety tests.