
Introduction of LangTest, an open-source Python toolkit for evaluating LLMs and NLP models 2024
The use of natural language processing (NLP) models, including the more recent large language models (LLM) in real-world applications obtained relevant success in the past years. To measure the performance of these systems, traditional performance metrics such as accuracy, precision, recall, and f1-score are used. Although it is important to measure the performance of the models in those terms, natural language often requires an holistic evaluation that consider other important aspects such as robustness, bias, accuracy, toxicity, fairness, safety, efficiency, clinical relevance, security, representation, disinformation, political orientation, sensitivity, factuality, legal concerns, and vulnerabilities.
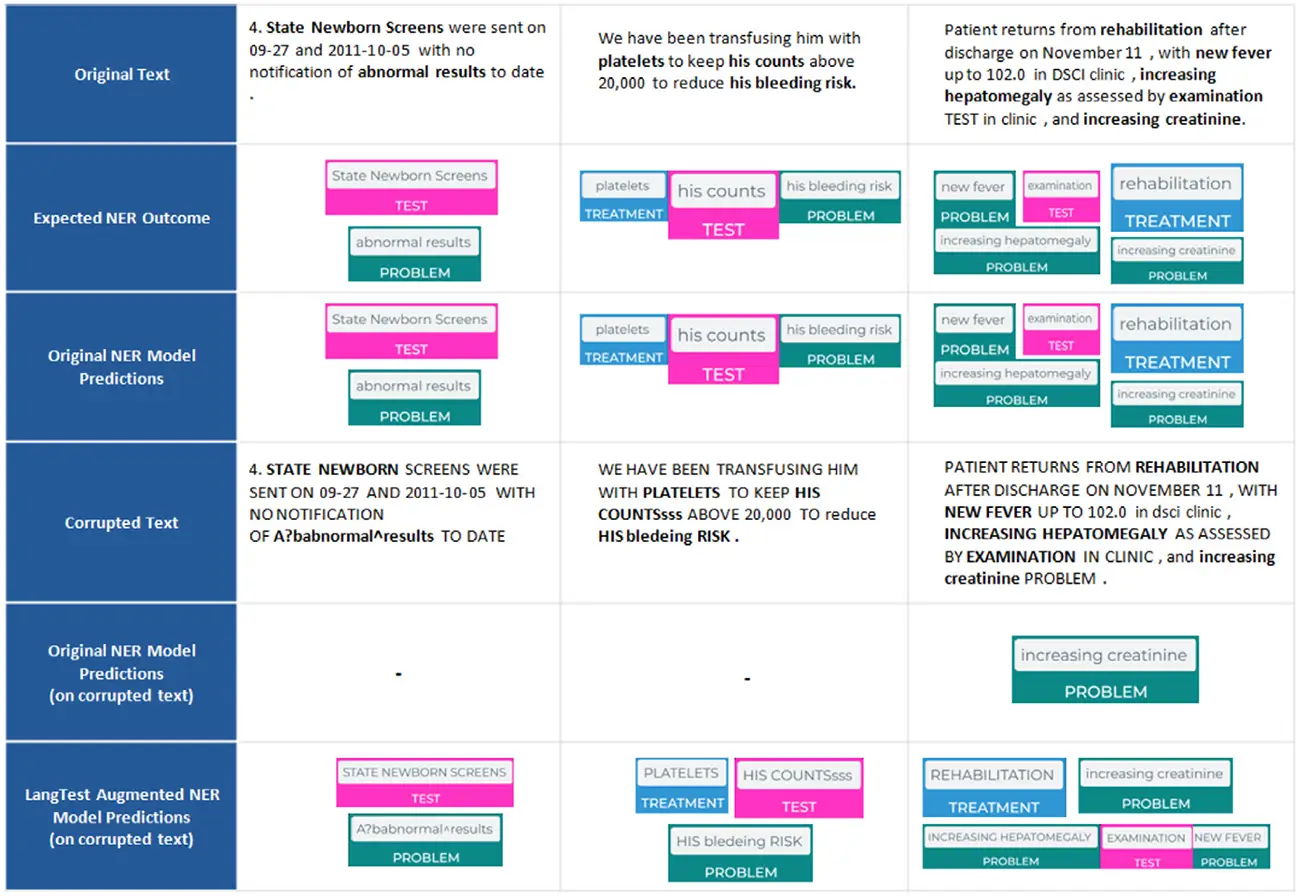
To address the gap, we introduce LangTest, an open source Python toolkit, aimed at reshaping the evaluation of LLMs and NLP models in real-world applications. The project aims to empower data scientists, enabling them to meet high standards in the ever-evolving landscape of AI model development. Specifically, it provides a comprehensive suite of more than 60 test types, ensuring a more comprehensive understanding of a model’s behavior and responsible AI use. In this experiment, a Named Entity Recognition (NER) clinical model showed significant improvement in its capabilities to identify clinical entities in text after applying data augmentation for robustness.
FAQ
What is LangTest and how does it support LLM evaluation?
LangTest is an open-source Python toolkit for evaluating LLMs and NLP models using over 60 test types—including accuracy, robustness, bias, fairness, and toxicity—through simple one‑line code, compatible with major frameworks.
Can LangTest assess models beyond text generation?
Yes. It supports a variety of NLP tasks—such as named entity recognition, translation, classification—and can integrate with models across Spark NLP, Hugging Face, OpenAI, Cohere, and Azure APIs.
What makes LangTest different from other evaluation tools?
Unlike traditional metrics like BLEU or F1, LangTest provides a holistic evaluation—covering robustness, bias, representation, fairness, safety, and more—within a unified, extensible framework.
How does LangTest handle robustness testing of LLMs?
It generates perturbations—such as typos, rephrasing, or casing changes—to test model resilience against adversarial inputs, and provides pass/fail metrics using LLM-based or string-distance evaluation.
What production features does LangTest provide for model comparison and governance?
LangTest offers benchmarking and leaderboard support, multi-model and multi-dataset evaluation, data augmentation, Prometheus eval integration, drug-name swapping, and safety tests.