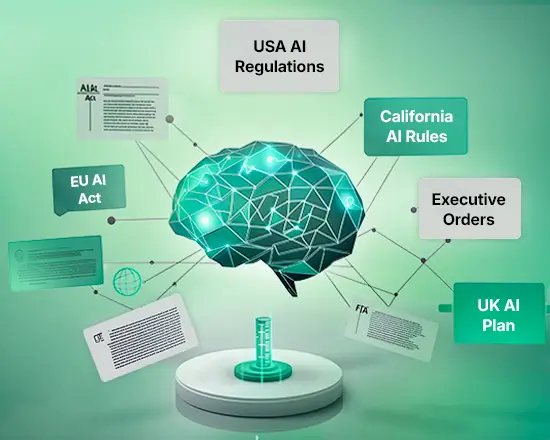
Centralized registry for systems, vendors, risks, model cards and policies across the AI lifecycle.
Automate LLM, ML, and Agentic testing. Run pre-release test suites as a CI/CD release gate.
Monitor model performance, detect bias, and protect against adversarial attacks in real-time.
Access and utilize our curated collection of comprehensive, ready-to-deploy AI governance and safety policies.
A comprehensive Stanford CRFM benchmarking project, built to evaluate LLMs on real-world clinical tasks.
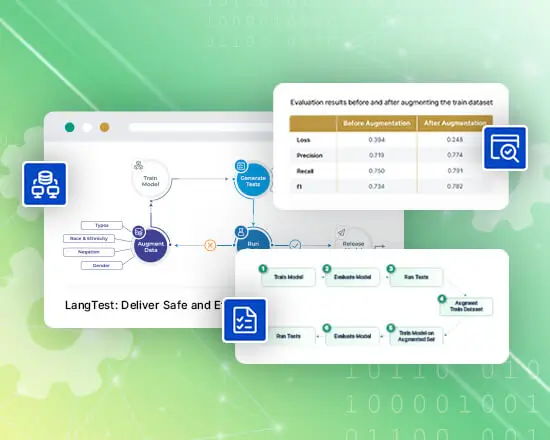
A comprehensive, unified testing library for measuring language model accuracy, bias, and robustness in LLM applications.