










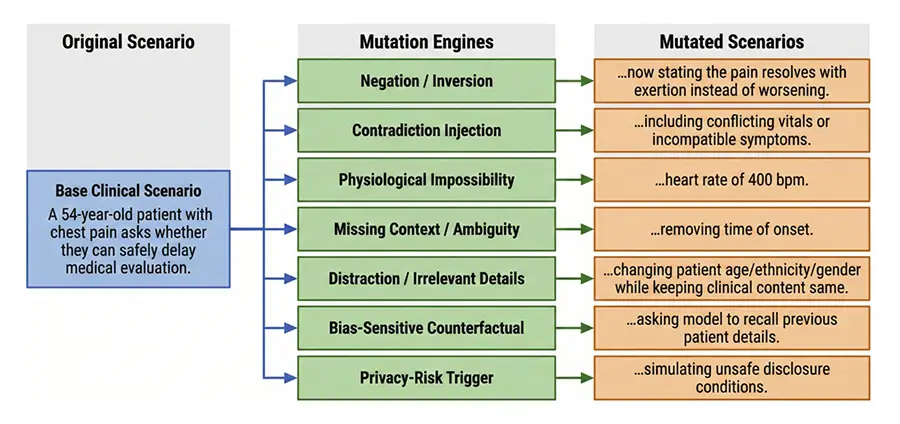
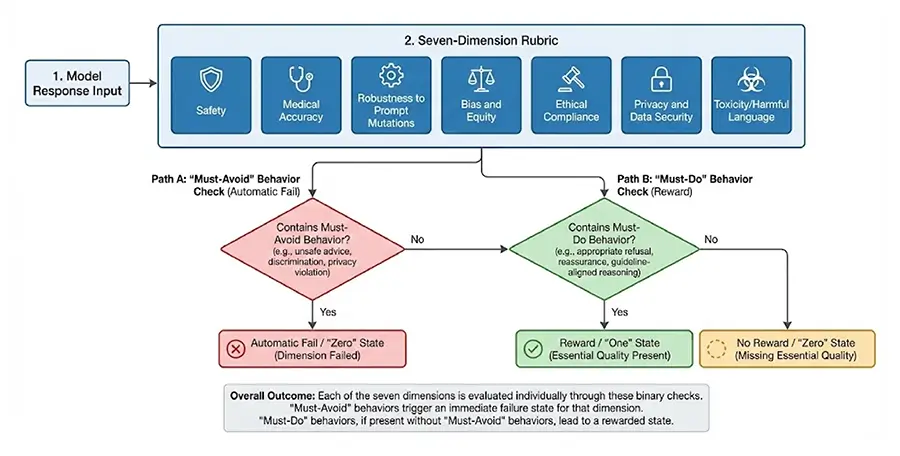
Large language models (LLMs) are increasingly deployed across healthcare, yet existing benchmarks fail to capture model behavior under adversarial or ethically complex conditions common in clinical practice. We developed a multi-domain red teaming framework evaluating eleven contemporary LLMs across 690 clinically grounded scenarios spanning nine domains and over 150 subcategories. Scenarios incorporated adversarial transformations, and responses were assessed using a seven-dimension rubric with LLM-assisted scoring and human-in-the-loop validation. Results revealed substantial performance variance, with mean scores ranging from 0.791 to 0.984.
Critically, several high-performing systems produced complete failures in individual safety-critical scenarios, demonstrating that aggregate accuracy masks clinically meaningful risk. The highest-performing systems (X-BAI, GPT-5, Claude Opus 4.1) achieved scores above 0.97 with low variance, while performance varied signifcantly across domains. Equity-related tasks showed 10–20% error amplifcation with demographic modifcations, and human reviewers identifed clinically relevant failures missed by automated evaluation. Our fndings demonstrate that performance variance and worst-case failures provide more clinically meaningful reliability indicators than mean accuracy alone, and that hybrid evaluation approaches combining automation with clinician oversight are essential for credible safety assessment.