










LangTest evaluates healthcare AI models across six core dimensions: accuracy, robustness, bias, fairness, representation, and data leakage. The version 2.7 clinical testing suite includes AMEGA (135 questions across 20 diagnostic scenarios spanning 13 medical specialties, peer-reviewed in npj Digital Medicine), MedFuzz adversarial fuzz testing (GPT-4 accuracy dropped from 87% to 62%), and drug name confusion testing across generic-to-brand and reverse conversions. Swap testing runs across more than 20 demographic dimensions.
A clinical NER model passes every benchmark your team runs. Accuracy looks clean. The test suite passes. Deployment goes ahead. Three weeks later, a pharmacist flags that the model is confusing two drug formulations. Consistently. Only in noisy handwritten inputs. The kind it encounters every single day in a real clinical setting.
Every benchmark was clean. Clinical robustness was never measured.
Why benchmark accuracy misses what clinical settings actually test
Accuracy is one dimension of model quality. In healthcare, it’s the easiest to measure and the least sufficient on its own.
Benchmark accuracy tells you that your model produced correct outputs on a curated test set. It tells you nothing about what happens when a patient’s name signals a particular ethnicity. Nothing about whether protected health information is appearing in model outputs. Nothing about whether performance degrades when inputs look the way real clinical data looks: abbreviated, misspelled, inconsistently formatted.
Adversarial robustness and clinical robustness are different failure modes. Standard security tooling addresses adversarial attacks and jailbreaks. Multi-Domain Red Teaming evaluates model behavior across adversarial, clinical, and edge-case scenarios that standard benchmarks miss.
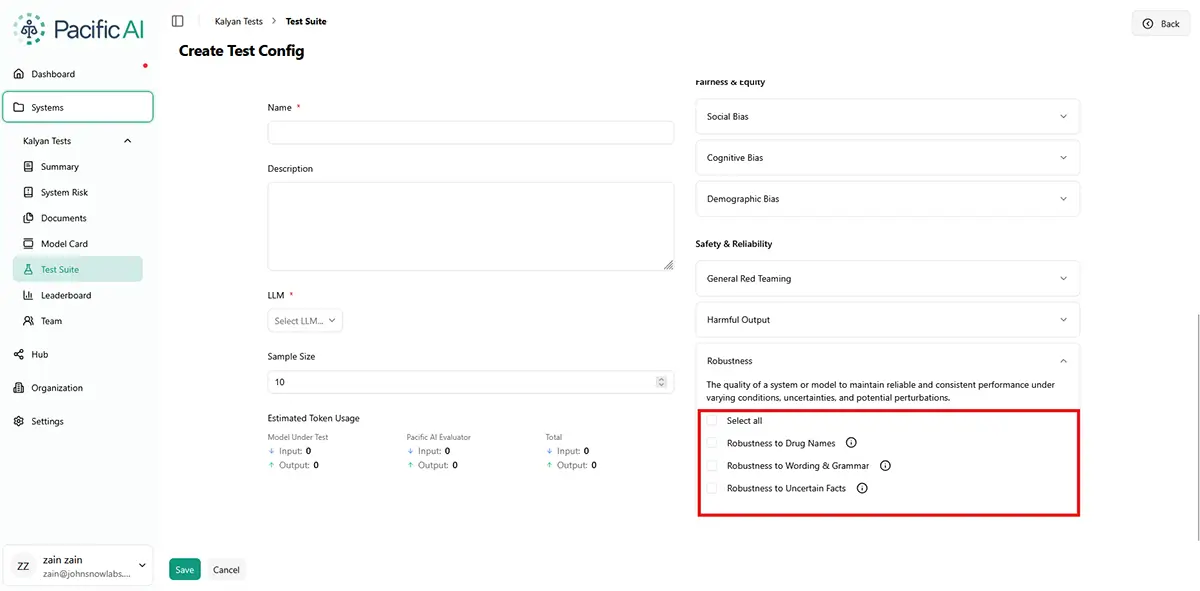
Robustness testing in the Pacific AI console
OpenAI’s acquisition of PromptFoo in March 2026 raised the profile of adversarial security testing. A model that resists jailbreaks may still fail systematically on handwritten drug names. Both failures matter; most evaluation programs address one.
If your current evaluation framework covers only security and accuracy, you’re clearing a bar that regulators and auditors no longer consider sufficient. The gap between what you have tested and what you are required to demonstrate is real. August 2026 is not a soft target.
What does the EU AI Act and ACA Section 1557 require from AI evaluation documentation

When the EU AI Act comes into full enforcement in August 2026, and under the ACA Section 1557 rule already in force in the US, what regulators and auditors want to see is specific: versioned, reproducible, structured test results showing that your model was evaluated across demographic dimensions, that failures were identified, and that concrete remediation steps were taken.
This is a higher bar, mandatory for high-risk AI systems in healthcare, hiring, credit, and public-sector applications. Understanding AI risk management is the first step. Building the technical infrastructure to demonstrate it is the second.
For models that touch clinical decisions, hiring, credit, or public-sector workflows, structured multi-dimensional evaluation is the minimum standard for deployment. If it wasn’t documented, it didn’t happen. The Joint Commission’s Responsible Use of AI in Healthcare (RUAIH) certification sets the same bar for U.S. health systems directly: it requires dated, ongoing evidence of bias testing and monitoring across an organization’s full AI estate, not a one-time evaluation.
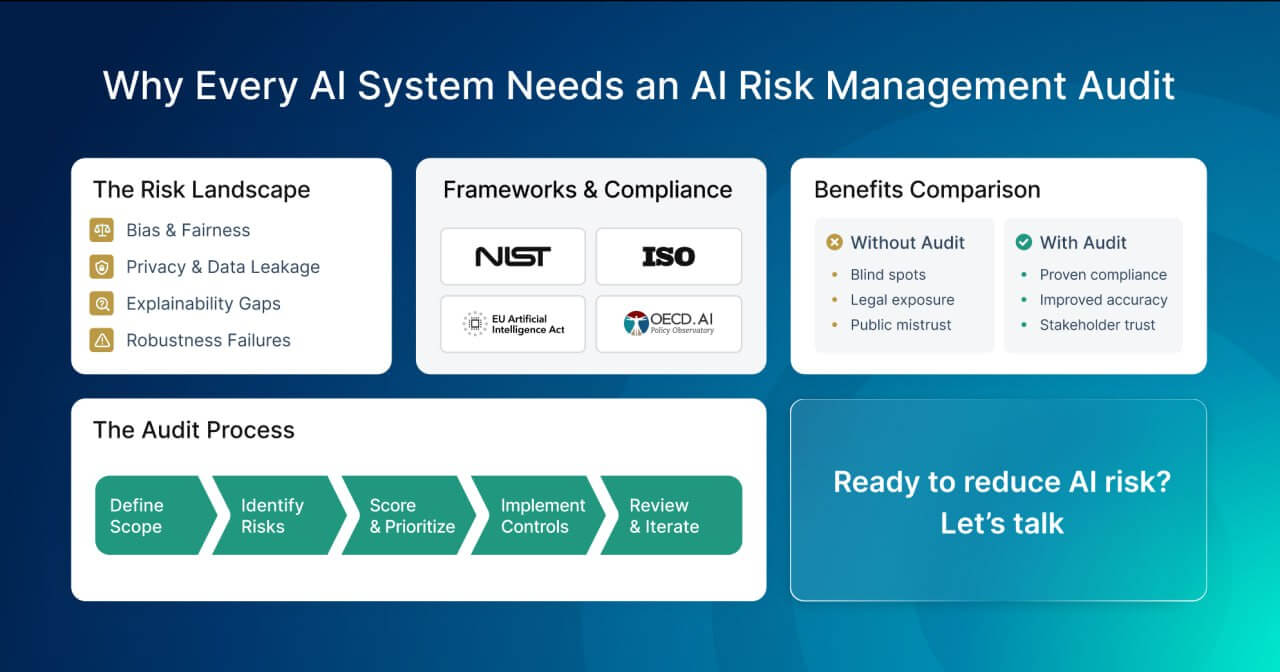
Six dimensions, each targeting a failure mode that benchmark accuracy alone cannot surface
LangTest, maintained by Pacific AI, was designed from the start to evaluate the full picture of model quality, not just accuracy. It is Apache 2.0 licensed, peer-reviewed, and published in Software Impacts (Elsevier, 2024), and ships major releases every 3 to 4 months.
Standard benchmark scoring surfaces one of those six: accuracy on curated test data. Robustness, bias, representation, and fairness don’t appear in a benchmark score. Data leakage is the sixth dimension: not a core accuracy metric, but a required check for any clinical or HIPAA-governed deployment where PHI must not surface in model outputs.
When you open LangTest, you’ll find over 100 tests in the product UI. The six dimensions group them as follows:
| Dimension | Assessment Focus | Summary | Business Relevance |
|---|---|---|---|
| Robustness | How the model behaves on dirty inputs: typos, casing variation, abbreviations, back-translation, rushed documentation. In clinical settings, this is not an edge case. It is the default condition. | Passing a benchmark on clean data tells you nothing about what happens on a real ward. | If your model was evaluated on structured, curated data but deployed into a clinical environment, you do not yet know its real performance. Three weeks into production is not when you want to find out. By then, the model is live, the vendor contract is signed, and the incident is already in the log. |
| Bias | Whether the model responds differently based on a patient’s name, origin, ethnicity, or gender. LangTest runs swap testing across more than 20 demographic dimensions, replacing names, pronouns, and cultural signals, and measuring whether outputs shift. | A model that responds differently to identical inputs because of a patient’s name creates both fairness and legal exposure. | ACA Section 1557 is already in force in the US. If a patient or advocacy group challenges a clinical AI decision on discrimination grounds and you can’t produce documented bias testing, the absence of that documentation is itself the problem. |
| Fairness | Whether the model performs equally across demographic groups at the aggregate level. Fairness testing measures group-level performance parity, so accuracy numbers can’t mask systematic underperformance for specific populations. | A model can be 89% accurate overall and still be significantly less accurate for the patients who need it most. | Aggregate accuracy is the number most teams report to leadership and to auditors. It’s also the number most likely to conceal the specific failure that creates liability. An 89% overall accuracy score can mask a 71% accuracy rate for a specific demographic group. |
| Representation | The demographic composition of the training data. Representation testing surfaces dataset imbalances that may not yet have produced measurable bias in outputs, but will. | The bias you cannot see yet is already in the training data. Representation testing finds it before it surfaces in production. | Many vendor-supplied models don’t include demographic breakdowns of training data. Deploying without representation testing means accepting undisclosed risk. Under the EU AI Act, demonstrating training data governance is part of the documentation requirement for high-risk systems. |
| Data Leakage | Whether sensitive terms, patient identifiers, or protected health information are appearing in model outputs where they shouldn’t. In healthcare, data leakage is a direct patient privacy risk and a HIPAA concern. | Without leakage testing, you have no visibility into whether PHI is appearing in your model’s outputs. | Under HIPAA, organizations are responsible for preventing PHI from surfacing in AI model outputs. A model that surfaces patient identifiers intermittently may create reportable breach exposure. Leakage testing is standard due diligence before any clinical deployment. |
| Accuracy | How accurately the model identifies, classifies, or generates clinically relevant information in real-world tasks, including entity recognition, classification, and contextual understanding. Accuracy must be evaluated beyond clean benchmarks, at the level of clinical correctness and decision impact. | A model can achieve high overall accuracy and still make critical errors in specific cases. In healthcare, a single incorrect entity, diagnosis, or recommendation is a patient safety risk. | Aggregate accuracy is the number most often reported to leadership and regulators. A model that performs well on benchmarks but fails on clinically relevant edge cases exposes organizations to safety incidents, regulatory scrutiny, and legal liability. Accuracy must be validated in context before deployment, not assumed from benchmark results. |
LangTest supports NER, text classification, translation, question answering, and summarization, with per-entity, per-label granularity for NLP tasks. Without evaluation across robustness, bias, fairness, representation, and data leakage, your accuracy score reflects performance on data you already had. It tells you nothing about what happens next.
Over 100 standardized test types across NER, classification, translation, and question answering
LangTest provides over 100 predefined test types that can be applied immediately across common NLP tasks. Teams can run standardized evaluation suites, compare model versions and configurations, test across multiple LLM endpoints, and integrate evaluation directly into development workflows.
LangTest’s most common test categories: Robustness, Fairness, Coverage, Age Bias, Origin Bias, Ethnicity Bias, Accuracy, Gender Representation, Data Leakage:

GPT-4 dropped from 87% to 62% under MedFuzz: what version 2.7 clinical testing suite measures
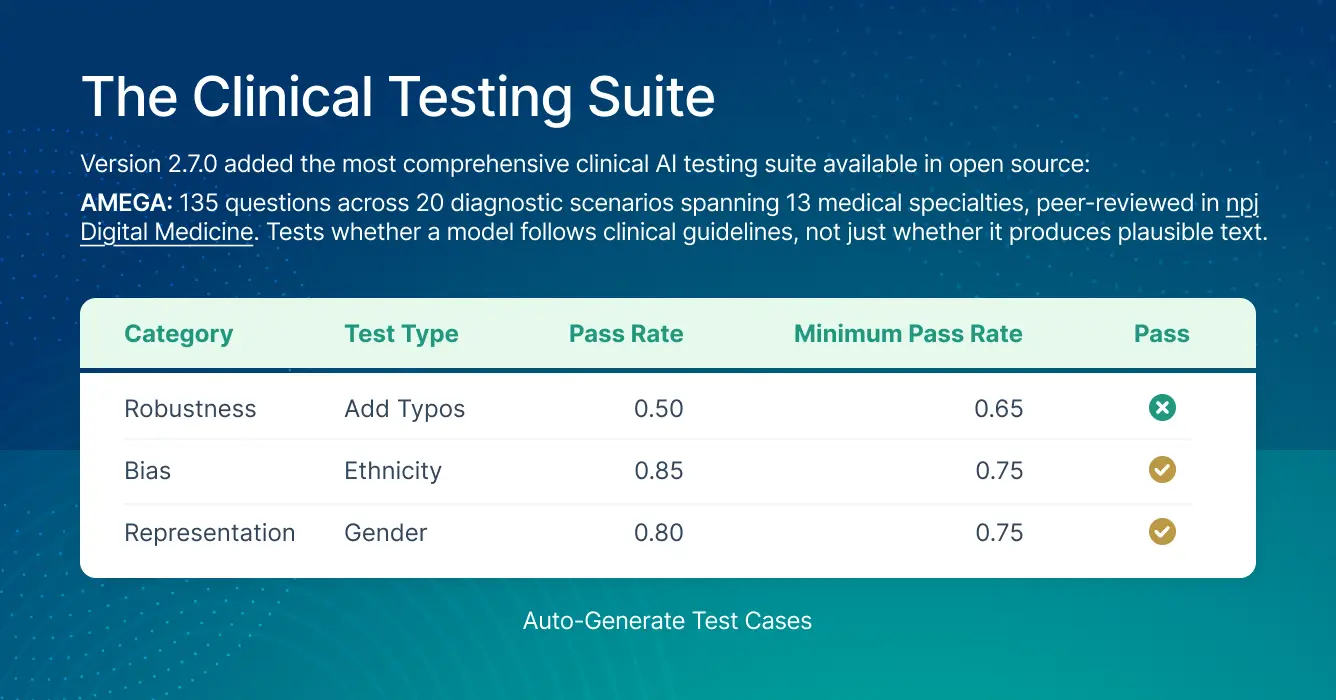
The latest LangTest Version 2.7 added the most clinically specific testing suite available in open source:
AMEGA: 135 questions across 20 diagnostic scenarios spanning 13 medical specialties, peer-reviewed in npj Digital Medicine. Tests whether a model follows clinical guidelines, not just whether it produces plausible text.
MedFuzz: adversarial fuzz testing for clinical settings, originally developed at Microsoft Research. GPT-4’s accuracy dropped from 87% to 62% under MedFuzz attacks. That 25-point gap is the distance between benchmark performance and real-world clinical performance.
Drug name confusion testing: generic-to-brand and reverse conversion. Metoprolol succinate and metoprolol tartrate are different medications with different dosing. Standard benchmarks don’t test for this.
ACI-Bench, MTS-Dialog, MentalChat16K: clinical note generation, doctor-patient dialogue, and mental health conversational AI evaluation.
To see how LangTest suites run as part of a 60+ test program spanning clinical tasks, cognitive bias, safety probes, and regulatory readiness, including a live CI/CD demo, join our June 10 webinar: Testing Healthcare AI in 2026: A Deep-Dive on 60+ Peer-Reviewed Evaluations.
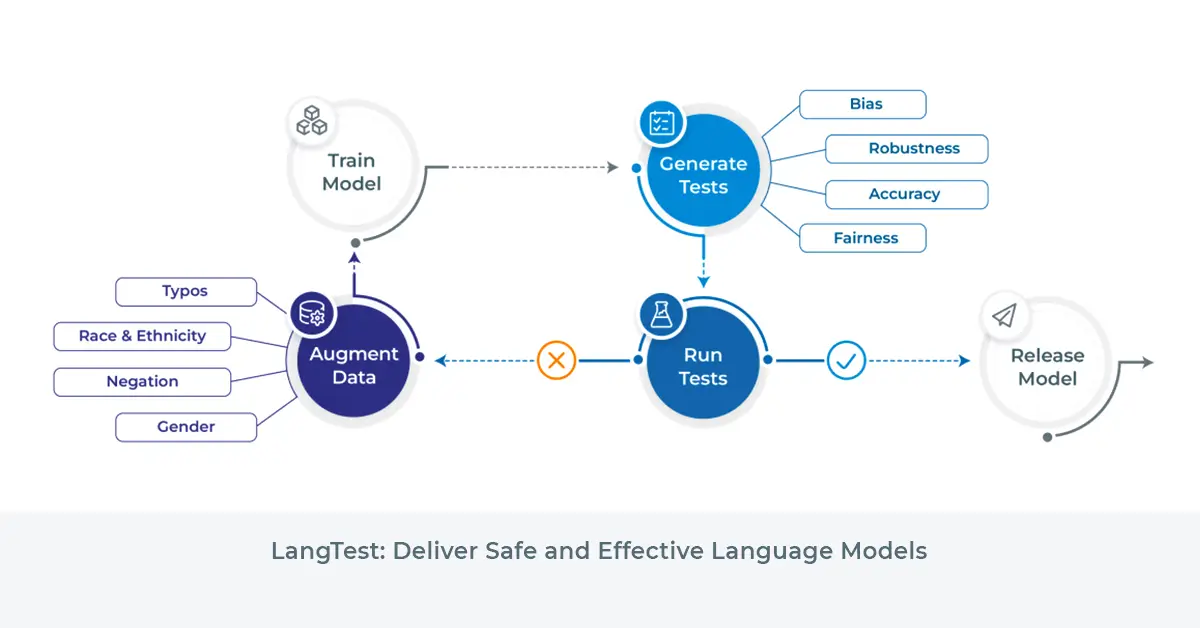
From failure to fix: detect, augment, retrain, re-test
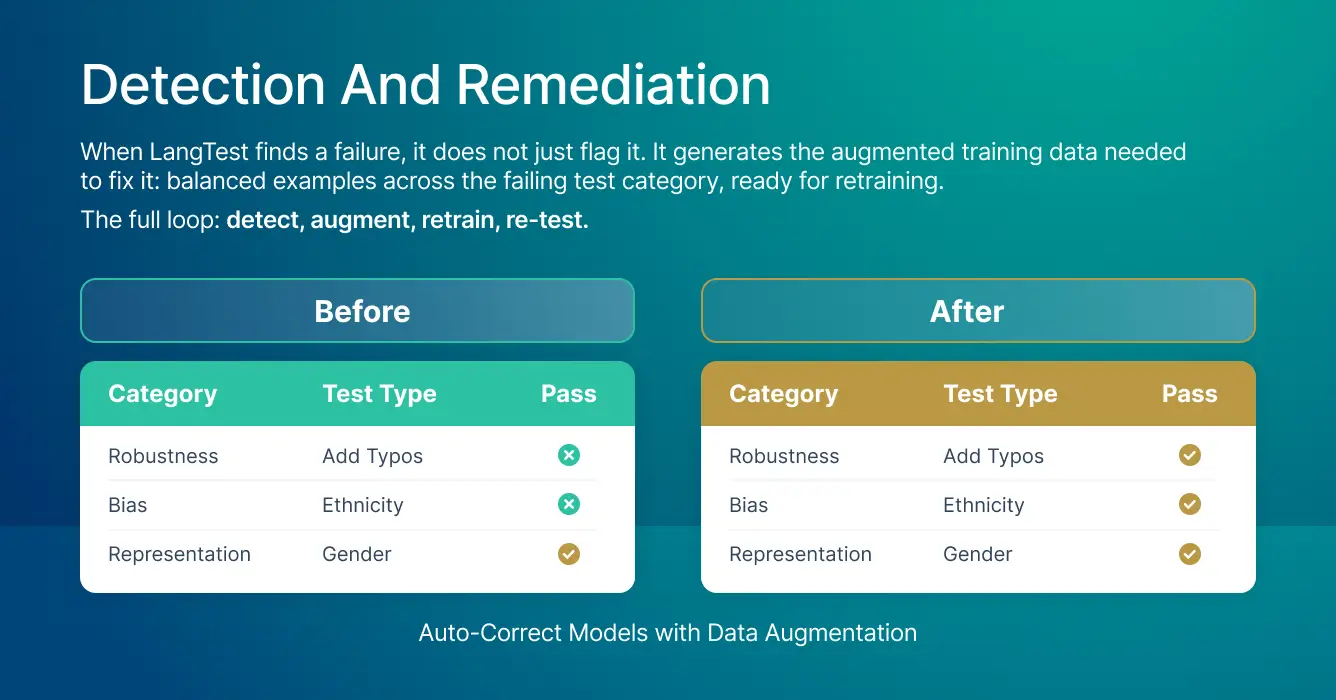
When LangTest finds a failure, it generates the augmented training data needed to fix it (for select models): balanced examples across the failing test category, ready for retraining.
The full loop: detect, augment, retrain, re-test.
That loop closes the gap between knowing you have a problem and being able to demonstrate you fixed it. The peer-reviewed methodology (Nazir et al., Software Impacts, Elsevier, 2024) can be cited directly in regulatory filings when you need to show an auditor how you evaluated and remediated your model.
How LangTest fits inside the Pacific AI Governance, Validation & Monitoring Platform
LangTest is the evaluation layer inside Pacific AI’s Gatekeeper. This is where teams typically first see the gap between benchmark performance and real-world reliability. Gatekeeper extends that evaluation into pre-release CI/CD gating. Guardian monitors deployed models continuously for accuracy drift, bias, and safety degradation.
Evaluation is one layer of a complete governance platform, alongside governance policies, automated risk assessment, and the Governor registry.
LangTest is purpose-built for healthcare: every test category, from drug name confusion to clinical note evaluation, is designed for the inputs and failure modes that clinical settings actually produce. Pacific AI is the only CHAI-certified AI Assurance Resource Provider covering all four layers. For agentic systems, where failures occur inside reasoning chains rather than at the output layer, see continuous red teaming for agentic healthcare AI.
Evaluation tells you whether a model works. Governance proves it is safe
Healthcare AI deployment requires performance plus the ability to audit, reproduce, and monitor systems across their lifecycle.
If you can’t document how a system behaves, it can’t be approved. If you can’t govern it across its lifecycle, it can’t be scaled.
Accuracy scores record how a model performed on data you already had. LangTest tests what happens on the data your model will actually encounter in production. Gatekeeper and Guardian keep that proof current after deployment.
See how Advisory & Managed Services can help you build the technical infrastructure from evaluation through production.
Most teams find the gaps after go-live. Take the AI Governance Quiz (10 min) to assess where you are now.
Frequently Asked Questions
What is the difference between adversarial robustness and clinical robustness?
Adversarial robustness tests whether a model resists deliberate attacks and jailbreaks. Clinical robustness tests whether it performs reliably on inputs it actually encounters: handwritten notes, abbreviations, OCR errors, and rushed documentation. These are different failure modes. Standard security tooling addresses adversarial robustness; LangTest addresses both.
What input perturbations does LangTest use to test robustness?
LangTest applies transformations including letter case changes, punctuation variations, typos, OCR errors, speech-to-text noise, abbreviation expansion, and synonym replacements. Each simulates a class of real-world input variation. Results are expressed as a pass rate above a defined threshold, making them interpretable and actionable.
What is the difference between bias testing and fairness testing?
Bias testing measures whether a model responds differently to identical inputs that differ only in demographic signals, such as a patient’s name or gender. Fairness testing measures whether a model performs equally across demographic groups in aggregate. A model can pass one and fail the other. LangTest runs both.
Why is data leakage testing required before clinical AI deployment?
Under HIPAA, organizations are responsible for preventing PHI from appearing in AI model outputs. A model that surfaces patient identifiers intermittently may create reportable breach exposure. Leakage testing confirms whether PHI is appearing in model outputs before the model goes live.
What do regulators require from AI evaluation documentation?
Under the EU AI Act, enforced from August 2026, and ACA Section 1557 already in force in the US, regulators require versioned, reproducible, structured test results showing evaluation across demographic dimensions, identified failures, and documented remediation steps. Versioned test results from LangTest, with per-dimension pass rates and documented remediations, address these documentation requirements directly. Organizations subject to these regulations should consult their own compliance counsel to determine what the rules require for their specific systems and operations.
